Foram encontradas 120 questões.
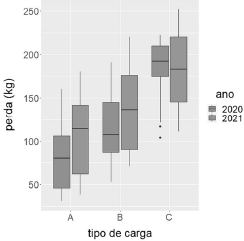
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
Suponha que os valores das quantidades de carga perdida sejam submetidos a uma normalização numérica com base no critério do Z-score da forma
!$ Z_{a,t} = { \large X_{a,t} - \mu_{a,t} \over \sigma_{a,t}} !$,
em que !$ X_{a,t} !$ denota a quantidade de carga do tipo t perdida no ano !$ a,\mu_{a,t} !$ representa a quantidade média de carga do tipo t perdida no ano a, e !$ \sigma_{a,t} !$ refere-se ao desvio padrão da distribuição da quantidade de carga do tipo t perdida no ano a. Como resultado dessa normalização, a média da soma
!$ Z_{2020,A} + Z_{2020,B} + Z_{2020,C} !$
será igual à média da soma
!$ Z_{2021,A} + Z_{2021,B} + Z_{2021,C} !$
Provas
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
No que se refere à distribuição da quantidade de carga do tipo B perdida em 2021, observa-se que o valor da perda mínima foi superior a
Q1 - 1,5Dq, no qual representa o primeiro quartil e Dq denota o intervalo interquartil da distribuição em tela.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Julgue o próximo item, relativo a redes neurais artificiais (RNA).
Em RNA, o uso de early stopping, ainda que não evite o overfitting, permite calcular com mais precisão a classificação nos dados de validação e, assim, melhorar a acurácia do treinamento.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os hiperparâmetros de um modelo são todos os parâmetros que podem ser definidos antes do inicio do treinamento, diferentemente dos parâmetros do modelo, que são aprendidos durante o treino do modelo. A busca por hiperparâmetros de determinado algoritmo de aprendizado de máquina que retorne o melhor desempenho medido em um conjunto de validação deu origem ao conceito de otimização de hiperparâmetros.
Acerca dos conceitos de otimização de hiperparâmetros de modelos de aprendizado de máquinas, julgue o item que se segue.
A otimização bayesiana se utiliza do conceito de probabilidade para encontrar o valor de entrada de uma função que possa retornar o menor valor de saída possível. Nesse método, o número de iterações de pesquisa pode ser reduzido a partir da escolha dos valores de entrada, levando em consideração os resultados anteriores, o que caracteriza um processo iterativo.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
No código a seguir, DecisionTreeClassifier é um classificador que recebe como entrada dois arrays: um array X, de valores inteiros, contendo os rótulos de classe para as amostras de treinamento; e um array Y, esparso ou denso, contendo as amostras de treinamento.
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os modelos ditos fracos, também chamados modelos de base, muitas vezes são combinados com o objetivo de se construir um modelo mais forte, no qual a variância e o viés atinjam equilíbrio satisfatório. Esse procedimento, denominado ensembles, é muito utilizado em ciência de dados e aprendizado de máquinas. Quanto às formas de ensembles, julgue o próximo item.
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Provas
Uma determinada repartição pública fez um levantamento do tempo , em minutos, que os cinco funcionários de uma sessão gastam para chegar ao trabalho em função da distância x, em quilômetros, de suas residências. O resultado da pesquisa realizada com cada um deles é apresentado na tabela a seguir, em que !$ \bar{x} !$ e !$ \bar{y} !$ são, respectivamente, as médias amostrais das variáveis x e y .
| i | tempo yi |
distância xi |
!$ x_i - \bar{x} !$ | !$ y_i -\bar{y} !$ | !$ ( x_i - \bar{x}) X (y_i - \bar{y}) !$ | !$ (x_i - \bar{x})^2 !$ |
| 1 | 10 | 5 | -4 | -7 | 28 | 16 |
| 2 | 20 | 5 | -4 | 3 | -12 | 16 |
| 3 | 15 | 10 | 1 | -2 | -2 | 1 |
| 4 | 10 | 10 | 1 | -7 | -7 | 1 |
| 5 | 30 | 15 | 6 | 13 | 78 | 36 |
| média | 17 | 9 |
Com base nos dados dessa tabela, julgue o próximo item.
Pelo modelo de regressão linear simples, a equação que expressa o relacionamento ajustado entre a variável em função de !$ x !$ e !$ \hat{y}_i = { \large 85 \over 70} x_i + \alpha !$, em que α é uma constante.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
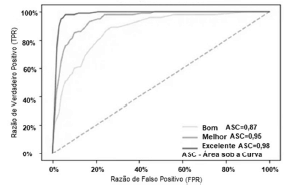
As curvas ROC a seguir mostram a taxa de especificidade (verdadeiros positivos) versus a taxa de sensibilidade (falsos positivos) do modelo adotado; a linha tracejada é a linha de base da métrica de avaliação e define uma adivinhação aleatória.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
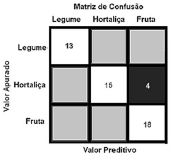
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
Provas
Mars is the fourth planet from the Sun — a dusty, cold, desert world with a very thin atmosphere. Mars is also a dynamic planet with seasons, polar ice caps, canyons, extinct volcanoes, and evidence that it was even more active in the past.
No other planet has captured our collective imagination quite like Mars.
In the late 1800s when people first observed the canal-like features on Mars’ surface, many speculated that an intelligent alien species resided there. This led to numerous stories about Martians, some of whom invade Earth, like in the 1938 radio drama, The War of the Worlds. According to an enduring urban legend, many listeners believed the story to be real news coverage of an invasion, causing widespread panic.
Countless stories since have taken place on Mars or explored the possibilities of its Martian inhabitants. Movies like Total Recall (1990 and 2012) take us to a terraformed Mars and a struggling colony running out of air. A Martian colony and Earth have a prickly relationship in The Expanse television series and novels.
Internet: <www.solarsystem.nasa.gov> (adapted).
Judge the followin item, based on the previous text.
According to the text, the speculations about extraterrestrial life started in the late 1800s due to canal-like features observed on Mars.
Provas
Caderno Container