Foram encontradas 1.730 questões.
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
No código a seguir, DecisionTreeClassifier é um classificador que recebe como entrada dois arrays: um array X, de valores inteiros, contendo os rótulos de classe para as amostras de treinamento; e um array Y, esparso ou denso, contendo as amostras de treinamento.
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os modelos ditos fracos, também chamados modelos de base, muitas vezes são combinados com o objetivo de se construir um modelo mais forte, no qual a variância e o viés atinjam equilíbrio satisfatório. Esse procedimento, denominado ensembles, é muito utilizado em ciência de dados e aprendizado de máquinas. Quanto às formas de ensembles, julgue o próximo item.
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Provas
Uma determinada repartição pública fez um levantamento do tempo , em minutos, que os cinco funcionários de uma sessão gastam para chegar ao trabalho em função da distância x, em quilômetros, de suas residências. O resultado da pesquisa realizada com cada um deles é apresentado na tabela a seguir, em que !$ \bar{x} !$ e !$ \bar{y} !$ são, respectivamente, as médias amostrais das variáveis x e y .
| i | tempo yi |
distância xi |
!$ x_i - \bar{x} !$ | !$ y_i -\bar{y} !$ | !$ ( x_i - \bar{x}) X (y_i - \bar{y}) !$ | !$ (x_i - \bar{x})^2 !$ |
| 1 | 10 | 5 | -4 | -7 | 28 | 16 |
| 2 | 20 | 5 | -4 | 3 | -12 | 16 |
| 3 | 15 | 10 | 1 | -2 | -2 | 1 |
| 4 | 10 | 10 | 1 | -7 | -7 | 1 |
| 5 | 30 | 15 | 6 | 13 | 78 | 36 |
| média | 17 | 9 |
Com base nos dados dessa tabela, julgue o próximo item.
Pelo modelo de regressão linear simples, a equação que expressa o relacionamento ajustado entre a variável em função de !$ x !$ e !$ \hat{y}_i = { \large 85 \over 70} x_i + \alpha !$, em que α é uma constante.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
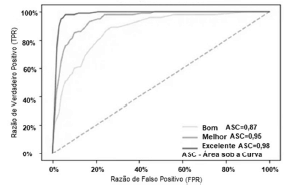
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
As curvas ROC a seguir mostram a taxa de especificidade (verdadeiros positivos) versus a taxa de sensibilidade (falsos positivos) do modelo adotado; a linha tracejada é a linha de base da métrica de avaliação e define uma adivinhação aleatória.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
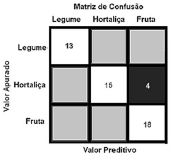
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
Provas
Considerando as técnicas relacionadas à mediação de conflitos e negociação, julgue o item seguinte.
O estilo de gestão de conflito caracterizado por não assertividade e não cooperação é denominado acomodação.
Provas
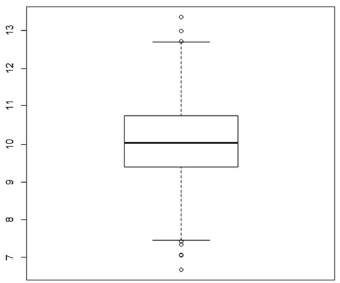
Com relação aos dados que resultaram no diagrama mostrado na figura precedente, julgue o item a seguir.
Nesse diagrama, a porção da distribuição dos dados representada pela parte inferior do diagrama mostrada a seguir representa exatamente 25% dos dados em questão.

Provas
Com relação aos dados que resultaram no diagrama mostrado na figura precedente, julgue o item a seguir.
A amplitude total dos dados em tela é inferior a 6.
Provas
Considerando que a variável aleatória X segue uma distribuição binomial com parâmetros !$ n=10 !$ e !$ p=0,1 !$, julgue o item subsequente.
O desvio padrão da distribuição de X é igual ou superior a 0,9.
Provas
A PETROBRAS busca atuar com responsabilidade social, incentivando o comportamento ético e transparente, a partir de códigos de conduta e do apoio a princípios como os previstos no Pacto Global, da Organização das Nações Unidas. Acerca de sustentabilidade e responsabilidade social, julgue o item que se segue.
As empresas integrantes do chamado Pacto Global assumem a responsabilidade de contribuir para o alcance de até três dos Objetivos de Desenvolvimento Sustentável (ODS).
Provas
Caderno Container