Foram encontradas 32.712 questões.
Um estatístico que necessitava prever a demanda de certo material escolar em uma região do estado, observou a Série Temporal semanal registrada dessa demanda Zt = {21, 20, 23, 20,19, 23, 24, 25}. Então, aplicou a técnica de alisamento das Médias Móveis Simples com 2 termos. A série temporal alisada obtida foi:
Provas
O tanque de gasolina de um posto não recebe abastecimento do combustível de forma completamente previsível. A entrega da gasolina ao posto, em qualquer dia, é igualmente provável para a altura do líquido na caixa de 1,5 m, 1,75 m ou 2,00 m. A demanda de gasolina é, também, variável e pode necessitar das quantidades equivalentes a 1,25 m, 1,50 m ou 1,75 m no tanque. Essa demanda também é equiprovável. Considerando o abastecimento de gasolina como a variável aleatória X e a demanda como a variável aleatória Y e as duas como independentes, é correto afirmar que
Provas
O Gráfico de Caixa e Bigodes a seguir representa uma amostra de observações.
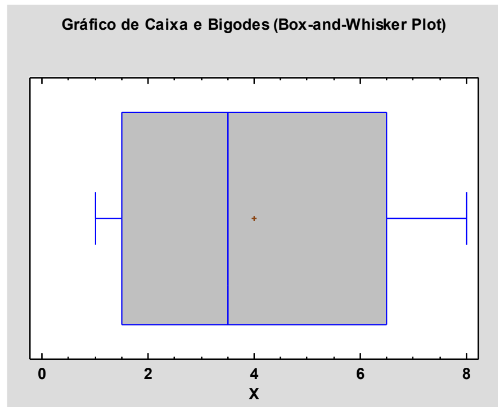
É correto afirmar que
Provas
Seja a amostra aleatória de tamanho n = 4, [5, 8, 2, 1]. A descrição numérica dessa amostra forneceu as seguintes estatísticas amostrais para estimar os parâmetros média, mediana, desvio-padrão, coeficiente de variação e erro padrão da média da distribuição de origem da amostra. Essas estatísticas são, respectivamente,
Provas
A mídia eletrônica brasileira divulgou recentemente que a Equipe de Pesquisa da WWWIQ Test apontou que o QI médio brasileiro é de 83. Um estatístico resolveu entrevistar uma amostra aleatória de tamanho n = 20 servidores públicos de certo órgão público aplicando o mesmo questionário teste do órgão internacional para testar a hipótese de que os servidores têm o mesmo QI médio dos brasileiros em geral. Teste com nível de significância de 5% para testar a hipótese nula H0: \( \mu \) = 83 contra a hipótese alternativa H1: \( \mu \) > 83. As estatísticas amostrais
obtidas foram: média amostral x = 92 e desvio- padrão s = 2 e a amostra foi aceita como oriunda
da Distribuição Normal. Com base nesses números, o estatístico pode afirmar corretamente que a estatística do teste foi de
Provas
Um estatístico criou no Programa Computacional R o gráfico temporal de um arquivo de compras efetuadas em 24 meses com largura de 4.875, altura de 2.5 e tamanho do ponto 8. O gráfico obtido foi o seguinte:

Os procedimentos que ele elaborou no R foram os seguintes:
entrou com o arquivo no R fazendo:
># Entrada dos dados
>compras=c(2815, 2672, ... , 6838, 8357)
>mês=c(1, 2, ... , 23, 24)
E, para obter o gráfico, o estatístico criou mais dois (2) comandos, sendo os seguintes:
Provas
O responsável pela administração de um órgão público necessita projetar o consumo mensal de certo produto usado rotineiramente nas escolas estaduais de certa região. Dessa forma, tomou uma amostra aleatória composta de n escolas da região e consultou os registros dos valores observados para o consumo do produto, que é a variável resposta a ser projetada Y e de outras três variáveis X1, X2 e X3 que estão correlacionadas com o consumo Y, mas são independentes entre si. Assim, ajustou um modelo linear aos dados e verificou se a premissa dos resíduos seguirem a Distribuição Normal (Gaussiana) era satisfeita, bem como se alguma variável independente (explicativa) poderia ser deixada de ser monitorada (descartada). Os resultados obtidos são:
Estimativas
| Parâmetro | Estimativa |
Erro Padrão |
Estatística t |
Valor-p |
| Intercepto | -38,686 | 15,3743 | -2,51627 | 0,0222 |
| X1 | 0,708 | 0,147167 | 4,81309 | 0,0002 |
| X2 | 1,381 | 0,409731 | 3,37034 | 0,0036 |
| X3 | -0,168 | 0,196399 | -0,855741 | 0,4040 |
Teste de Normalidade de Shapiro-Wilk W = 0,978 Valor-p => p = 0,909 É correto afirmar, considerando o nível de significância de 5% nos testes, que
Provas
Um grande complexo administrativo do estado possui um número de funcionários igual a N servidores. O responsável pela administração desse órgão público necessita estimar o consumo médio de certo produto por funcionário. Sendo assim, precisa obter uma amostra aleatória de tamanho n dos N servidores para entrevistá-los e conseguir os dados. De experiências anteriores, é conhecido o desvio-padrão σ da variável aleatória correspondente ao consumo do produto. Com as informações da população finita N e do desvio-padrão σ da variável aleatória, o estatístico responsável pelo plano amostral fixou um erro de amostragem (precisão) em d e a amplitude para o intervalo de confiança é 2d. Ainda, fixou o nível de confiança da estimativa em \( 1 - \alpha \) e em correspondência obteve o escore padronizado de \( Z\dfrac{\alpha}{2} \). Finalmente, dimensionou o tamanho da amostra em
Provas
Suponha a amostra aleatória \( [X_1,X_2,...,X_n] \) de uma população (distribuição) \( N(\um, \sigma^2) \) e considere os estimadores dos parâmetros \( \mu \)e \( \sigma^2 \), respectivamente, \( \overline{x} \) e \( \hat{\sigma}^2=\dfrac{\Sigma^n_{i=1}(x_1-\overline{x}^2}{n} \). Então, o vício e o erro quadrático médio do estimador \( \hat{\sigma}^2 \) são, respectivamente,
Provas
Seja a amostra aleatória [\( X_1 \), \( X_2 \), ... , \( X_n \)] de uma v.a. com distribuição de probabilidade \( N(\mu, \sigma^2) \). Então, o estimador UMVU do parâmetro \( \mu \) tem a seguinte distribuição amostral:
Provas
Caderno Container