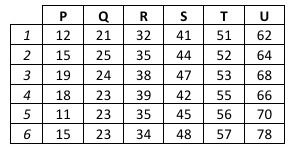
A tabela a seguir apresenta a distribuição de dados
numéricos nas linhas 1 a 6, das colunas P a U:
A partir da tabela, tem-se que: G = média aritmética dos dados
da coluna P; H = mediana dos dados da linha 2; I = média
aritmética dos dados da coluna U; J = mediana dos dados da
linha 5; K = média aritmética dos dados da coluna S; L =
mediana dos dados da linha 6; M = média aritmética dos dados
da coluna T; N = mediana dos dados da linha 1. Com base em
todas essas informações, assinale a alternativa que traz o
resultado da expressão:
O CREF22-ES estabeleceu a regra: “Se o profissional
não cumprir as horas de educação continuada, então
será advertido”. Também analisou as idades de seus
funcionários, que são 28, 30, 32, 35, 36, 38, 41 anos.
Com base nessa situação hipotética, julgue o item a seguir.
Depois de 2 anos, a média das idades dos
funcionários aumentará em 2 unidades, assim como o
desvio padrão.
O CREF22-ES estabeleceu a regra: “Se o profissional
não cumprir as horas de educação continuada, então
será advertido”. Também analisou as idades de seus
funcionários, que são 28, 30, 32, 35, 36, 38, 41 anos.
Com base nessa situação hipotética, julgue o item a seguir.
A mediana das idades dos funcionários é de 35 anos.
Um professor do IFPE e sua equipe estão desenvolvendo um modelo de previsão da cota da barragem
Tapacurá em Pernambuco. O modelo utilizará as variáveis IP(Índice Pluviométrico), medida em mm, e
cota_da_barragem, medida em cm (da base da barragem ao topo). Após tratarem os valores ausentes e
normalizarem os dados, avançam para a fase de Feature Engineering. O objetivo principal do modelo é prever
a cota da barragem com um dia de antecedência, utilizando o histórico das variáveis. Considerando que a cota
de uma barragem é um fenômeno com forte dependência temporal, dado que a chuva de hoje influencia a cota
da barragem de amanhã, marque a opção que contém a estratégia mais adequada para o objetivo principal do
modelo apresentado.
Suponha que você participa de um projeto de mineração de dados e está treinando um modelo de árvore de
decisão para um problema de classificação com três categorias: Frutas Cítricas, Frutas Doces e Frutas
Oleaginosas. Em um determinado nó da árvore, a distribuição das 80 amostras de treinamento é a seguinte:
Frutas Cítricas: 40 amostras
Frutas Doces: 20 amostras
Frutas Oleaginosas: 20 amostras
Com base nessa distribuição, os valores do Índice de Gini e da Entropia, em bits, são dados, respectivamente,
por:
A matriz de confusão, relacionada ao resultado na base de teste de um modelo de classificação binária,
encontrou os seguintes resultados: 60 verdadeiros positivos, 400 verdadeiros negativos, 20 falsos positivos e
60 falsos negativos. Com base nesses valores, o resultado do F1-Score é
Um cientista de dados utiliza validação cruzada k-fold para avaliar o desempenho de um classificador. Sobre a
razão de usar essa técnica, é correto afirmar que a validação cruzada
Durante o treinamento de um modelo de regressão polinomial, o cientista de dados observa que o erro no
conjunto de treino é muito baixo, mas o erro no conjunto de teste é elevado. Analise as afirmativas a seguir e
assinale a que caracteriza corretamente esse fenômeno.