Foram encontradas 32.711 questões.
O comprimento X das fibras de algodão é uma das características determinantes da qualidade da produção na indústria têxtil. Suponha que a variável X tenha distribuição Normal com média μ e desvio padrão σ que dependem do fornecedor. Uma indústria recebe um lote dessas fibras, que podem ter vindo do fornecedor A ou do fornecedor B, cujos parâmetros na distribuição de X são, respectivamente: !$ ( \mu_A = 33; \sigma_A = 3) !$ e !$ ( \mu_B = 36; \sigma_A = 6) !$. Para decidir se o lote veio do fornecedor A (hipótese H0) ou do fornecedor B (hipótese H1), a indústria resolve selecionar uma amostra de tamanho “n” das fibras do lote e, se o comprimento médio das fibras selecionadas for grande !$ ( \bar{x} > K) !$, onde k é uma constante, a indústria decide que o lote veio do fornecedor B; caso contrário, decide que veio do fornecedor A. Considere a seguinte tabela, que apresenta quantis da distribuição Normal de média zero e desvio padrão um.
Quantis da distribuição
Normal Z, de média zero e desvio padrão um.
|
Zc |
2,33 | 2,05 | 1,88 | 1,75 | 1,64 | 1,28 |
| !$ P ( Z \le Z_c) !$ | 0,01 | 0,02 | 0,03 | 0,04 | 0,05 | 0,10 |
Qual é o valor aproximado de “n” de forma que as probabilidades de cometer o Erro Tipo I e o Erro Tipo II sejam ambas iguais a 0,05?
Provas
Sabe-se que, na última safra, o custo médio do frete de itens agrícolas, para distâncias em torno de 800 km, foi de R$ 350,00 com um desvio padrão de R$ 75,00. Para a safra atual, os produtores adotaram novas estratégias no planejamento e na logística do transporte da produção, a fim de diminuir esse custo médio. Assumindo que as novas estratégias não modificaram o desvio padrão do custo na safra atual e supondo normalidade na distribuição da variável custo, deseja -se verificar se as mudanças foram eficazes. Para o teste das hipóteses de interesse, foram registrados os custos do frete na safra atual (para distâncias em torno de 800 km) de uma amostra de 25 produtores, cuja média e desvio padrão amostral foram, respectivamente, !$ \bar{x} = R$ 305,00 !$ e s = R$ 70,00. Assim, o p-valor (ou nível descritivo) do teste é aproximadamente p = 0,0013, e conclui-se que as mudanças foram eficazes na redução do custo. Seja Z uma variável com distribuição Normal de média zero e desvio padrão um, e seja !$ \bar{X} !$ a estatística que representa a média amostral, o p- valor foi obtido como a seguinte probabilidade:
Provas
0,041João e Antônio são atletas de tiro esportivo, cujas chances de acertarem o alvo são 90% e 75%, respectivamente. Suponha que um deles é selecionado ao acaso e executa 6 tiros. Para decidir qual deles executou os tiros, adotou-se a regra: se o atirador acertar o alvo nos 6 tiros, diremos que o João foi o atirador; caso contrário, diremos que foi o Antônio. Usando a tabela da distribuição Binomial a seguir, obtenha as probabilidades dos Erros Tipo I e Tipo II, definidos como: Erro Tipo I: dizer que os tiros foram dados pelo João, quando, na realidade, foram dados pelo Antônio. Erro Tipo II: dizer que os tiros foram dados pelo Antônio, quando, na realidade, foram dados pelo João.
Distribuição Binominal: valores da função de probabilidade $f_x (X) = P(X = x) = { \begin{pmatrix} n\\x \end{pmatrix}} p^x ( 1 - p)^{ n- x}$
| p | ||||||||||||||||||||
| n | x | 0,05 | 0,1 | 0,15 | 0,2 | 0,25 | 0,3 | 0,35 | 0,4 | 0,45 | 0,5 | 0,55 | 0,6 | 0,65 | 0,7 | 0,75 | 0,8 | 0,85 | 0,9 | 0,95 |
| 6 | 0 | 0,735 | 0,531 | 0,377 | 0,262 | 0,178 | 0,118 | 0,075 | 0,047 | 0,028 | 0,016 | 0,008 | 0,004 | 0,002 | 0,001 | 0,000 | 0,000 | 0,000 | 0,000 |
0,000 |
| 1 | 0,232 | 0,354 | 0,399 | 0,393 | 0,356 | 0,303 | 0,244 | 0,187 | 0,136 | 0,094 | 0,061 | 0,037 |
0,020 |
0,010 | 0,004 | 0,002 | 0,000 | 0,000 |
0,000 |
|
| 2 | 0,031 | 0,098 | 0,176 | 0,246 | 0,297 | 0,324 | 0,328 | 0,311 | 0,278 | 0,234 | 0,186 | 0,138 | 0,095 | 0,060 | 0,033 | 0,015 | 0,005 | 0,001 |
0,000 |
|
| 3 | 0,002 | 0,015 | 0,041 | 0,082 | 0,132 | 0,185 | 0,235 | 0,276 | 0,303 | 0,313 | 0,303 | 0,276 | 0,235 | 0,185 | 0,132 | 0,082 | 0,041 | 0,015 |
0,002 |
|
| 4 | 0,000 | 0,001 | 0,005 | 0,015 | 0,033 | 0,060 | 0,095 | 0,138 | 0,186 | 0,234 | 0,278 | 0,311 | 0,328 | 0,324 | 0,297 | 0,246 | 0,176 | 0,098 |
0,031 |
|
| 5 | 0,000 | 0,000 | 0,000 | 0,002 | 0,004 | 0,010 | 0,020 | 0,037 | 0,061 | 0,094 | 0,136 | 0,187 | 0,244 | 0,303 | 0,356 | 0,393 | 0,399 | 0,354 |
0,232 |
|
| 6 | 0,000 | 0,000 | 0,000 | 0,000 | 0,000 | 0,001 | 0,002 | 0,004 | 0,008 | 0,016 | 0,028 | 0,047 | 0,075 | 0,118 | 0,178 | 0,262 | 0,377 | 0,531 |
0,735 |
|
As probabilidades dos Erros Tipo I e Tipo II são, respectivamente,
Provas
A fim de combater o desperdício e diminuir o consumo (em kWh: Quilowatt-hora) de energia elétrica em empresas de pequeno porte de uma região, uma consultoria especializada foi contratada e implementou algumas medidas para melhorar a eficiência energética. Para acompanhar a redução no consumo de energia com as novas medidas, a consultoria selecionou uma amostra de n = 16 empresas da região e registrou o consumo antes (variável X) e após (variável Y) a implementação das medidas propostas. Foram observados, antes das novas medidas, um consumo médio entre as empresas selecionadas $\bar{x} =350 KWh$ e, após as novas medidas, um consumo médio $\bar{x} =320 KWh$. Suponha que a diferença entre os consumos, D = X - Y, segue uma distribuição Normal, e que o desvio padrão dessas diferenças entre as empresas selecionadas foi SD = 40 kW/h. Deseja-se testar a hipótese de que houve redução no consumo com as novas medidas.
Com base na tabela a seguir e adotando um nível de significância de 5%, qual é a região crítica do teste (RC) e a decisão tomada?
Distribuição t-Student com k graus de liberdade: valores de t tais que $P (-t \le T_k \le t) = 1 - p$
| $\rightarrow { \begin{matrix} p \\K\end{matrix}}$ | 90% | 80% | 70% | 60% | 50% | 40% | 30% | 20% | 10% | 5% | 4% | 2% | $\leftarrow { \begin{matrix} p \\K\end{matrix}}$ |
| 15 | 0,128 | 0,258 | 0,393 | 0,536 | 0,691 | 0,866 | 1,074 | 1,341 | 1,753 | 2,131 | 2,249 | 2,603 | 15 |
| 16 | 0,128 | 0,258 |
0,392 |
0,535 | 0,690 | 0,865 | 1,071 | 1,337 | 1,746 | 2,120 | 2,235 | 2,584 | 16 |
| 17 |
0,128 |
0,257 | 0,392 | 0,534 | 0,689 | 0,863 | 1,069 | 1,333 | 1,740 | 2,110 | 2,224 | 2,567 | 17 |
Provas
Uma forma de comparar as médias μx e μy de duas populações normais independentes X e Y, respectivamente, com variância comum e desconhecida σ2, é através do Intervalo de confiança para a diferença entre as médias, dado por
!$ \bar{x} - \bar{y} \pm q_t x S_p x \sqrt{ { \large 1 \over n} + { \large 1 \over m}}, !$
com !$ \bar{x} !$ representando a média observada em uma amostra aleatória de tamanho n da população X, !$ \bar{y} !$ a média observada em uma amostra aleatória de tamanho m da população Y, Sp é o desvio padrão amostral combinado observado nas amostras, e qt é um quantil da distribuição t-Student. Se y é o coeficiente de confiança desejado no intervalo e Tc representa a distribuição t-Student com c graus de liberdade, o quantil qt deve satisfazer a seguinte probabilidade:
Provas
No processo de estimação de parâmetros associados à distribuição de uma variável aleatória X, através de intervalos de confiança baseados no método da quantidade pivotal, pode-se afirmar que
Provas
Com relação às propriedades dos estimadores e aos diferentes métodos de estimação, pode-se afirmar que
Provas
A fim de estimar a probabilidade θ de sucesso em uma população X ~ Bernoulli (θ), foi conduzido o seguinte experimento em duas etapas: inicialmente, observou -se uma amostra aleatória X1, … , Xn, de tamanho n e, em seguida, observou-se uma nova amostra aleatória !$ X_{ n + 1}, \cdots, X_{n +m} !$, de tamanho m, independentemente da primeira amostra. Suponha que os seguintes estimadores estão sendo propostos para θ:
!$ \hat{ \theta}_1 = { \large 1 \over n} \sum_{i =1}^n X_i^2 !$ e !$ \hat{ \theta}_2 = { \large 1 \over 2} { \begin{pmatrix} { \large 1 \over n} \sum_{ i =1}^n X_i + { \large 1 \over m} \sum_{ i = n+ 1}^{n + m} X_i \end{pmatrix}} !$ Uma das propriedades desejáveis de um estimador é que ele tenha um erro quadrático médio pequeno. O estimador !$ \hat{ \theta}_2 !$ terá erro quadrático médio menor que o estimador !$ \hat{ \theta}_2 !$ terá erro quadrático médio menor que o estimador !$ \hat{ \theta}_1 !$ se, e somente se:
Provas
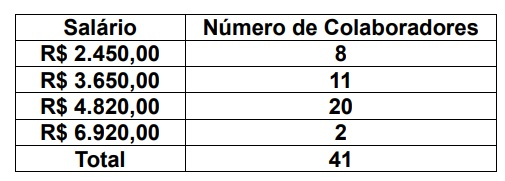
Com base na tabela o salário mediano da escola é igual a:
Provas
- Estatística DescritivaMedidas de Tendência CentralMédiasMédia AritméticaMédia Ponderada (Agrupados por Valor)
Observe a quantidade de filhos por funcionários de uma determinada empresa:
|
Quantidade de Funcionários |
Quantidade de filhos |
| 7 | 1 |
| 8 | 2 |
| 10 | 3 |
| 4 | 4 |
| 3 | 5 |
A média da quantidade de filhos é:
Provas
Caderno Container