Foram encontradas 5.143 questões.
Em Big Data, coleções ou grupos de dados relacionados em que
haja possibilidade de compartilhamento com outros grupos,
atributos ou propriedades são denominados
Provas
Questão presente nas seguintes provas
O aspecto diretamente afeto aos “Vs” de Big Data que trata
especificamente de ruído nos dados que não podem ser
convertidos em informações é
Provas
Questão presente nas seguintes provas
O aspecto diretamente afeto aos “Vs” de Big Data que trata
especificamente dos diferentes tipos de dados, ou seja, se são
estruturados ou semiestruturados, é a
Provas
Questão presente nas seguintes provas
Especificamente em relação a Big Data, o termo velocidade está
relacionado
Provas
Questão presente nas seguintes provas
Assinale a opção em que é apresentado o termo de Big Data que
se refere a uma massiva quantidade de informações que é uma
característica crítica na determinação de seu valor.
Provas
Questão presente nas seguintes provas
Assinale a opção que descreve corretamente a forma como o
Power BI, após a importação de dados para um modelo, gerencia
as relações e a atualização desses dados.
Provas
Questão presente nas seguintes provas
Em business intelligence (BI), a análise descritiva
Provas
Questão presente nas seguintes provas
Uma das camadas que compõem a arquitetura de
DW (data warehouse) consiste em um servidor OLAP que
possibilita velocidades de consulta rápidas; nessa camada,
três tipos de modelos OLAP podem ser utilizados (ROLAP,
MOLAP e HOLAP) e o tipo de sistema de banco de dados
existente no DW determinará o modelo de OLAP a ser utilizado.
Trata-se da camada
Trata-se da camada
Provas
Questão presente nas seguintes provas
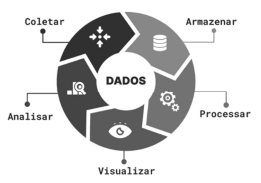
Entre as etapas do ciclo de dados do BI apresentadas na figura precedente, aquela em que os dados brutos são preparados e transformados em um formato adequado para análise é denominada
Provas
Questão presente nas seguintes provas
Julgue os itens a seguir, a respeito de ferramentas de
visualização de dados.
I Os gráficos de linhas são os mais adequados para acompanhar a evolução de uma variável ao longo do tempo. II Os histogramas classificam os dados de acordo com o valor de várias categorias. III Os gráficos de dispersão são usados para visualizar a relação entre duas variáveis contínuas.
Assinale a opção correta.
I Os gráficos de linhas são os mais adequados para acompanhar a evolução de uma variável ao longo do tempo. II Os histogramas classificam os dados de acordo com o valor de várias categorias. III Os gráficos de dispersão são usados para visualizar a relação entre duas variáveis contínuas.
Assinale a opção correta.
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container