Foram encontradas 5.143 questões.
Em arquiteturas modernas de Data Warehousing, o processo de ETL é fundamental para preparar os dados de forma eficiente para a tomada de decisões estratégicas.
Ele é como uma ponte entre os sistemas e o Data Warehouse. Nesse contexto, o principal objetivo do processo de ETL em uma solução de Data Warehousing é
Provas
Um conjunto de dados foi particionado em dois subconjuntos, sendo um de treinamento e outro de testagem, ambos utilizados exclusivamente para serem usados em seus objetivos originais (dados de treino para treinamento, e de teste para testagem).
Em relação ao ajuste e validação de modelos em aprendizado de máquina, um modelo sofre overfitting quando
Provas
A Inteligência Artificial (IA) é uma área da ciência da computação que visa desenvolver sistemas capazes de realizar tarefas que normalmente exigiriam inteligência humana.
O conceito que está mais diretamente relacionado ao desenvolvimento de sistemas que aprendem com os dados e melhoram seu desempenho ao longo do tempo é o de
Provas
Seja o código em R a seguir:

Analisando o código apresentado, sem a necessidade de executálo, é correto deduzir que
Provas
Considere o seguinte cenário: Uma empresa de telecomunicações está analisando os dados de uso de seus clientes, como frequência de chamadas, uso de dados móveis e envio de mensagens. Ela quer identificar grupos de clientes com comportamentos semelhantes para oferecer promoções personalizadas.
Em uma escolha por uma solução de aprendizado de máquina, o cientista de dados deve observar que, se o aprendizado for
Provas
O algoritmo de redução de dimensionalidade conhecido como Análise de Componentes Principais (PCA – Principal Component Analysis) possui características importantes.
Dada a escolha de um número k de componentes principais e um conjunto de dados X com cinco variáveis A, B, C, D e E, o PCA
Provas
Algoritmos de agrupamento podem ser classificados em diferentes categorias. Um algoritmo de agrupamento amplamente utilizado em aprendizado de máquina e mineração de dados é conhecido como K-Means.
O K-Means, em sua versão original, é classificado como um tipo de algoritmo
Provas
Considere o seguinte conjunto de transações em uma loja de varejo:
| Transação | Itens adquiridos |
|---|---|
| 1 | Leite, Pão, Manteiga |
| 2 | Leite, Pão |
| 3 | Leite, Manteiga |
| 4 | Pão, Manteiga |
| 5 | Leite, Pão, Queijo |
| 6 | Manteiga, Queijo |
A partir desse conjunto de transações, produz-se a regra de associação R: Leite → Pão Nesse contexto, é correto afirmar que a métrica de R que possui valor igual a 50% é
Provas
A companhia aérea Flying to the Moon sabe que o peso das bagagens despachadas por passageiro é uma variável aleatória com média μ=20 kg e desvio padrão σ=5 kg. Em um voo com capacidade máxima de 100 passageiros, todos os assentos estão ocupados.
Observações:
• Considere que a distribuição da soma pode ser aproximada por uma distribuição normal;
• Nomeando de Z a variável padronizada (escore-z), utilize a tabela a seguir, se julgar necessário.
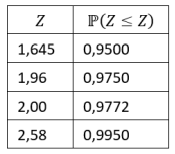
A probabilidade de que o peso total das bagagens neste voo exceda 2100 kg, e assim, ultrapasse o limite de segurança estabelecido, é igual a
Provas
Uma empresa multinacional está desenvolvendo uma plataforma avançada de Business Intelligence (BI) para integrar e analisar dados provenientes de diversas unidades de negócio ao redor do mundo. As fontes de dados incluem:
Sistemas transacionais estruturados: bancos de dados relacionais de ERP e CRM que armazenam informações sobre vendas, clientes e operações internas.
Dados semiestruturados: arquivos XML e JSON contendo registros de transações online e interações de usuários em aplicativos móveis.
Dados não estruturados: logs de servidores web, postagens em redes sociais, emails de suporte ao cliente dados de sensores IoT.
A empresa planeja implementar um Data Warehouse com um modelo multidimensional otimizado para permitir análises complexas e operações de OLAP que suportem a tomada de decisões estratégicas.
Durante o projeto, a equipe enfrenta os seguintes desafios:
Integração de dados heterogêneos: unificar dados estruturados, semiestruturados e não estruturados em um ambiente coeso.
Modelagem e otimização: desenvolver um modelo multidimensional que atenda às necessidades analíticas complexas, mantendo o desempenho.
Definição de hierarquias e granularidades: estabelecer níveis adequados de detalhe para suportar operações de OLAP como drill-down e roll-up.
Com base nesse cenário, avalie as afirmativas a seguir:
I. Para mapear as fontes de dados heterogêneas, é essencial utilizar metadados padronizados que descrevam a estrutura, o significado e a qualidade dos dados, facilitando sua integração no Data Warehouse.
II. Na modelagem multidimensional, a adoção de um esquema em floco de neve (snowflake schema), com tabelas de dimensões normalizadas, melhora o desempenho das consultas OLAP em comparação com o esquema estrela (star schema).
III. As operações de OLAP permitem análises em múltiplas dimensões; por exemplo, o slice fixa um valor em uma dimensão, enquanto o dice cria um subcubo selecionando valores específicos em múltiplas dimensões.
IV. A implementação de uma política de governança de dados clara e abrangente é fundamental para garantir a qualidade, consistência, segurança e privacidade dos dados ao longo de todo o ciclo de vida do projeto de BI.
Está correto o que se afirma em
Provas
Caderno Container