Foram encontradas 5.143 questões.
Considere o código em Python abaixo que será executado em condições ideais.
from sklearn.datasets import load_iris
from sklearn.model selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
iris = load_iris()
X = iris.data
y = iris.target
_I_
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y pred = knn.predict(X_test)
accuracy = accuracy score(y_test, y_pred)
print (f"Acurácia do modelo: {accuracy * 100:.2f}%")
Para que o programa divida o conjunto de dados em treino e teste na proporção de 80% treino e 20% teste, a lacuna I deve ser corretamente preenchida por:
Provas
Questão presente nas seguintes provas
É possível estabelecer uma classificação dos dados de uma organização em dados estruturados e dados não estruturados, sobre os quais é correto afirmar que
Provas
Questão presente nas seguintes provas
3536324
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Python e R são linguagens amplamente utilizadas para
análise de dados, machine learning e desenvolvimento
científico. Ambas possuem bibliotecas poderosas, mas
têm diferenças significativas em sua sintaxe e aplicação.
Qual das alternativas a seguir descreve corretamente
uma vantagem da linguagem R em comparação ao
Python em análise de dados?
Provas
Questão presente nas seguintes provas
3536320
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
No contexto de Data Warehousing, bases de dados
multidimensionais são estruturadas para facilitar o
processamento analítico e a geração de relatórios de
forma eficiente. A modelagem e a otimização dessas
bases exigem a aplicação de técnicas que garantam
desempenho e escalabilidade, suportando as operações
de OLAP (Online Analytical Processing). Relacione as
técnicas de modelagem com suas respectivas descrições
ou objetivos.
Coluna A: Técnica de Modelagem e Otimização.
1.Modelo Estrela (Star Schema). 2.Tabelas Fato e Dimensão. 3.Indexação Bitmap. 4.Modelo Snowflake (Floco de Neve). 5.Materialização de Visões.
Coluna B: Descrição
(__)Técnica de otimização que armazena pré-calculados os resultados de consultas frequentes, reduzindo o tempo de resposta nas consultas complexas.
(__)Técnica de indexação usada para bases de dados com alta cardinalidade, facilitando consultas por meio de índices binários.
(__)Estrutura de modelagem que simplifica a análise, mantendo todas as dimensões ligadas diretamente à tabela fato, otimizando a performance de consulta.
(__)Tabelas usadas para armazenar dados detalhados e sumarizados, com a tabela fato contendo medidas e as dimensões contendo atributos.
(__)Modelo de dados que normaliza as tabelas de dimensão, reduzindo redundâncias e aumentando a complexidade das junções.
A sequência correta é:
Coluna A: Técnica de Modelagem e Otimização.
1.Modelo Estrela (Star Schema). 2.Tabelas Fato e Dimensão. 3.Indexação Bitmap. 4.Modelo Snowflake (Floco de Neve). 5.Materialização de Visões.
Coluna B: Descrição
(__)Técnica de otimização que armazena pré-calculados os resultados de consultas frequentes, reduzindo o tempo de resposta nas consultas complexas.
(__)Técnica de indexação usada para bases de dados com alta cardinalidade, facilitando consultas por meio de índices binários.
(__)Estrutura de modelagem que simplifica a análise, mantendo todas as dimensões ligadas diretamente à tabela fato, otimizando a performance de consulta.
(__)Tabelas usadas para armazenar dados detalhados e sumarizados, com a tabela fato contendo medidas e as dimensões contendo atributos.
(__)Modelo de dados que normaliza as tabelas de dimensão, reduzindo redundâncias e aumentando a complexidade das junções.
A sequência correta é:
Provas
Questão presente nas seguintes provas
3536291
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Provas:
Data Mining e Cubos OLAP são ferramentas essenciais
para análise de grandes volumes de dados, permitindo
que analistas obtenham informações estratégicas para
tomada de decisões. No contexto de um Data
Warehouse, essas tecnologias têm papéis
complementares. Qual das alternativas abaixo descreve
corretamente a aplicação dessas ferramentas no
processo de análise de dados?
Provas
Questão presente nas seguintes provas
3536271
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Provas:
O DTS (Data Transformation Services) é uma ferramenta
utilizada para transformar e migrar dados entre diferentes
sistemas em um ambiente de Data Warehouse. Sabendo
disso, qual das alternativas abaixo reflete corretamente uma funcionalidade do DTS em um processo de ETL
(Extract, Transform, Load)?
Provas
Questão presente nas seguintes provas
3536268
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Provas:
Um esquema de banco de dados define como os dados
são organizados em um banco de dados relacional; isso
inclui restrições lógicas, como nomes de tabelas,
campos, tipos de dados e relacionamentos entre essas
entidades. Um esquema em floco de neve apresenta a
seguinte característica:
Provas
Questão presente nas seguintes provas
3535372
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Provas:
O NumPy (Numerical Python) é uma poderosa biblioteca
Python que é usada principalmente para realizar cálculos
em matrizes multidimensionais. Considerando o input
abaixo, a saída do código é:
my_array = np.array([[4, 5], [6, 1]])
print(my_array[0][1])
my_array = np.array([[4, 5], [6, 1]])
print(my_array[0][1])
Provas
Questão presente nas seguintes provas
3535361
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Disciplina: TI - Ciência de Dados e BI
Banca: Instituto Acesso
Orgão: Câm. Manaus-AM
Provas:
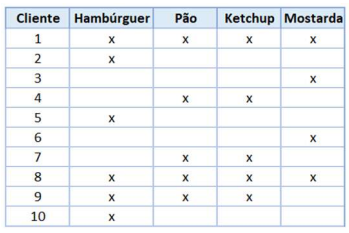
A associação é uma técnica de mineração de dados que
possui como princípio a utilização de algumas regras para encontrar relacionamentos entre variáveis, inclusive
em situações em que elas, aparentemente, não possuem
nenhuma relação. Considerando a realização de
compras por 10 clientes como demonstrado abaixo,
pode-se afirmar que o valor do suporte e confiança para
a associação "hambúrguer e pão" é, respectivamente,
de:
Provas
Questão presente nas seguintes provas
3526625
Ano: 2024
Disciplina: TI - Ciência de Dados e BI
Banca: Consulplan
Orgão: Pref. Campos Goytacazes-RJ
Disciplina: TI - Ciência de Dados e BI
Banca: Consulplan
Orgão: Pref. Campos Goytacazes-RJ
Provas:
O Big data é estruturado seguindo os conceitos dos 5 V’s; assinale-os.
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container