Foram encontradas 32.711 questões.
As Equações de Estimação Generalizadas (Generalized Estimating Equations – GEE)
foram desenvolvidas com o objetivo de fornecer estimativas consistentes e eficientes dos parâmetros
de modelos de regressão em situações em que os dados apresentam correlação. Esse método tem
sido amplamente empregado em análises de dados longitudinais e outros cenários com medidas
repetidas. Com base nos pressupostos e características dos modelos GEE, assinale a alternativa
correta.
Provas
Questão presente nas seguintes provas
Os Modelos de Equações de Estimação Generalizadas (Generalized Estimating
Equations – GEE) não exigem a suposição de esfericidade, pois permitem especificar diretamente a
estrutura de correlação entre medidas repetidas. A matriz de correlação de trabalho (working
correlation matrix) é uma estimativa dessa estrutura de dependência, utilizada para ajustar
corretamente os erros padrão e gerar estimativas robustas dos efeitos populacionais. No SPSS, ao
realizar uma análise GEE, é possível escolher entre cinco opções de matrizes de correlação para ajuste
dos modelos. Nesse contexto, relacione a Coluna 1 à Coluna 2, associando as seguintes matrizes às
suas respectivas características.
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Provas
Questão presente nas seguintes provas
Um estudo clínico tem como objetivo avaliar o efeito de uma intervenção cirúrgica
sobre o peso corporal, verificando se a cirurgia resulta em uma redução significativa do peso em
comparação ao grupo que não foi submetido ao procedimento. Para isso, os pacientes foram divididos
em dois grupos: caso (submetidos à cirurgia) e controle (sem cirurgia). O peso corporal foi mensurado
em dois momentos: antes da cirurgia (peso basal) e três meses após a cirurgia (peso pós-cirurgia),
ou apenas após 3 meses, para o grupo controle. Considere os seguintes planejamentos estatísticos:
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
Provas
Questão presente nas seguintes provas
Estudo sobre Diabetes Tipo 2: Um pesquisador busca identificar os fatores associados à
probabilidade de um indivíduo desenvolver diabetes tipo 2. Para isso, foram coletados
dados de 200 participantes e ajustado um modelo de regressão logística binária no software
SPSS, considerando as seguintes variáveis explicativas:
• Idade (em anos): variável quantitativa contínua.
• Sexo (masculino/feminino): variável categórica com o masculino definido como
categoria de referência.
O resultado da análise no SPSS apresentou o seguinte output:
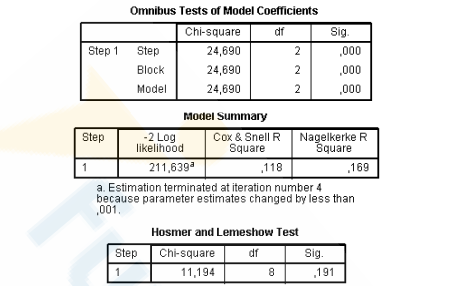
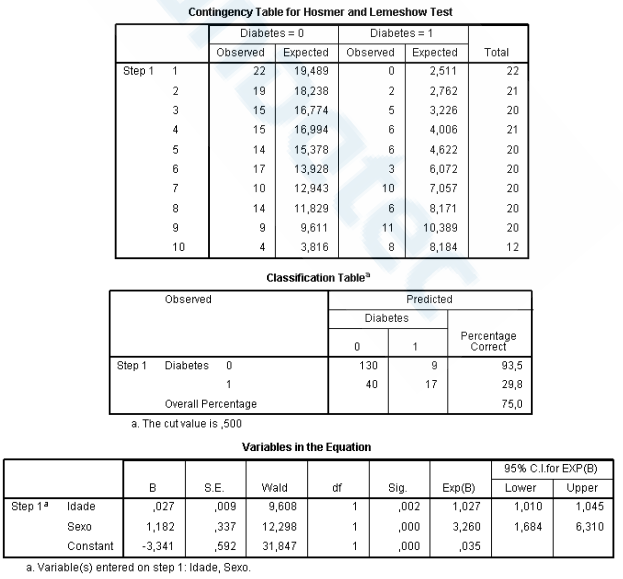
O _____________________ é utilizado para avaliar o ajuste global de um modelo de regressão logística, comparando os valores observados e previstos da variável dependente. A interpretação é direta: _______ indica um _____ ajuste. O teste é fácil de interpretar, amplamente usado em artigos científicos e fornece uma visão global do ajuste do modelo, mas tem limitações: em amostras grandes, pode detectar diferenças muito pequenas (excesso de sensibilidade) e, em amostras pequenas, pode não identificar problemas de ajuste, sendo recomendado combiná-lo com outras métricas e a análise de resíduos.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Provas
Questão presente nas seguintes provas
Estudo sobre Diabetes Tipo 2: Um pesquisador busca identificar os fatores associados à
probabilidade de um indivíduo desenvolver diabetes tipo 2. Para isso, foram coletados
dados de 200 participantes e ajustado um modelo de regressão logística binária no software
SPSS, considerando as seguintes variáveis explicativas:
• Idade (em anos): variável quantitativa contínua.
• Sexo (masculino/feminino): variável categórica com o masculino definido como
categoria de referência.
O resultado da análise no SPSS apresentou o seguinte output:
Provas
Questão presente nas seguintes provas
Considere o modelo de regressão linear simples: yi = a + bxi + ei com i = 1, …, n,
tal que ei é o componente aleatório de yi . Sobre as suposições necessárias para que os estimadores
de mínimos quadrados ordinários (MQO) sejam eficientes, assinale a alternativa correta.
Provas
Questão presente nas seguintes provas
Um professor de educação física elaborou 2 programas de treino (programa A e
programa B) e quer aplicar em um grupo de 24 alunos, a fim de testar suas eficiências
quanto ao ganho de resistência em um determinado período de tempo. Entretanto, ele
percebeu que, entre esses 24 alunos, existem 3 níveis de condicionamento físico (baixo,
médio e alto). Para controlar essa fonte de variação, o professor estratificou os alunos por
nível de condicionamento e, em cada nível, selecionou aleatoriamente 4 alunos para o
Programa A e 4 alunos para o Programa B, de modo que cada nível contém o mesmo número
de observações por treino.
Considere, ainda, que o ganho de resistência dos alunos será avaliado pela diferença entre
a distância percorrida em 12 minutos de caminhada/corrida, medida antes e após o período
de treinamento.
Os dados coletados incluem:
• Aluno: Identificador do aluno.
• Programa: A ou B.
• Nível: Baixo, médio ou alto.
• Resistência: Diferença entre a distância percorrida antes e após o período de treinamento.

Com base no código e nos resultados observados, analise as assertivas abaixo e assinale a alternativa correta.
I. A estatística de teste F, para comparar os programas, pode ser calculada a partir da soma dos quadrados e dos graus de liberdade, tal que F = 18,60, aproximadamente.
II. Se a hipótese nula for verdadeira, o valor de F tende a 1. Mas se a hipótese nula for falsa, o valor de F tende a ser maior que 1.
III. Mesmo com valor de p <0,05, para avaliar o efeito do programa, ainda é necessário o uso de testes “pós-ANOVA”, também conhecidos como testes post-hoc, para identificar qual programa apresentou maior ganho de resistência.
IV. O erro residual estimado (Residual standard error = 20.63461) indica a variabilidade média explicada pelo modelo.
Provas
Questão presente nas seguintes provas
Um professor de educação física elaborou 2 programas de treino (programa A e
programa B) e quer aplicar em um grupo de 24 alunos, a fim de testar suas eficiências
quanto ao ganho de resistência em um determinado período de tempo. Entretanto, ele
percebeu que, entre esses 24 alunos, existem 3 níveis de condicionamento físico (baixo,
médio e alto). Para controlar essa fonte de variação, o professor estratificou os alunos por
nível de condicionamento e, em cada nível, selecionou aleatoriamente 4 alunos para o
Programa A e 4 alunos para o Programa B, de modo que cada nível contém o mesmo número
de observações por treino.
Considere, ainda, que o ganho de resistência dos alunos será avaliado pela diferença entre
a distância percorrida em 12 minutos de caminhada/corrida, medida antes e após o período
de treinamento.
Os dados coletados incluem:
• Aluno: Identificador do aluno.
• Programa: A ou B.
• Nível: Baixo, médio ou alto.
• Resistência: Diferença entre a distância percorrida antes e após o período de treinamento.
Provas
Questão presente nas seguintes provas
No contexto da Análise Fatorial Exploratória (AFE), o software SPSS oferece diversos
procedimentos e opções de extração, rotação e verificação da adequação dos dados. Com base nesse
contexto, assinale a alternativa correta.
Provas
Questão presente nas seguintes provas
No campo da análise multivariada, existem diferentes técnicas estatísticas, cada uma
com finalidades específicas, como redução de dimensionalidade, identificação de variáveis latentes ou
agrupamento de casos semelhantes. Com base nesse contexto, assinale a alternativa abaixo que
corresponde à Análise de Agrupamentos (Cluster Analysis).
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container