Foram encontradas 300 questões.
Sobre Inferência Bayesiana analise as seguintes afirmativas:
l. Esta é uma área da estatística que não faz nenhum uso da função de verossimilhança.
ll. É um importante ramo da estatística, nesta área de estudo é possível que o pesquisador incorpore informações prévias sobre os parâmetros que se deseja estudar.
lll. Pode ser usada nos estudos de Aprendizagem de Máquina.
lV. Em muitas situações, quando não é possível encontrar distribuições a posteriori fechadas, esta teoria fará forte uso de método computacionais, dentre os quais podem-se citar o Algoritmo de Metropólis e o Amostrador de Gibbs, ambos baseados em Cadeias de Markov Monte Carlo (MCMC).
Tendo como base estas afirmações, pode-se concluir que o número de afirmativas verdadeiras é
Provas
Em análise de Modelos de Regressão Linear Múltipla uma ação importante para o pesquisador é a seleção de variáveis explicativas que irão entrar no modelo final. Para isso há algumas estratégias diferentes. A seguir apresentamos a ideia geral de uma destas estratégias (sem maiores detalhes):
• Passo 1: ajustar o modelo completo de k variáveis;
• Passo 2: retirar do modelo completo obtido no passo 1, a variável com menor valor da estatística t (ou maior valor de p); caso todas as variáveis apresentem p ≤ a , o processo é interrompido e o modelo final é selecionado.
• Passo 3: ajustar o modelo com k – 1 variáveis e voltar ao passo 2.
Com base nestas informações, o método de seleção de variáveis que mais se assemelha aos passos descritos no algoritmo indicado anteriormente é
Provas
Sobre alguns testes de hipóteses paramétricos, analise as seguintes afirmações:
l. O teste t-Student para uma amostra faz uso da suposição de normalidade dos dados.
ll. O teste t-Student para amostras pareadas é indicado para verificar se duas amostras independentes de tamanhos diferentes são provenientes de populações com mesma média.
lll. O teste F é específico para verificar se duas amostras são provenientes de populações com mesma média.
lV. O teste de Shapiro–Wilk pode ser utilizado para verificar se os dados são provenientes de uma população Normal.
Tendo como base estas afirmações, pode-se concluir que o número de afirmativas verdadeiras é
Provas
Quando algumas pressuposições do teste F da análise da variância não são satisfeitas, pode ser recomendado que o pesquisador faça uso dos chamados testes não paramétricos. Considerando que as pressuposições para análise de variância foram violadas, um dos testes não paramétricos a ser utilizado em substituição ao teste F é o teste
Provas
Considere uma amostra aleatória \( X_1, X_2, \cdots, X_n \) com cada \( X_i \) igualmente e independentemente distribuído, provenientes de uma população Normal com média \( \mu \) e variância \( \sigma^2 \). Sobre o processo de estimação pontual para os parâmetros desta população são realizadas as seguintes afirmações:
l. A média amostral calculada por \( \bar{X}_n = { \large \sum_{i=1}^n X_i \over n} \) é um estimador não tendencioso para \( \mu \).
ll. A variância amostral calculada por \( s^2 = { \large \sum_{i=1}^n (X_i - \bar{X}_n)^2 \over n -1} \) um estimador não tendencioso para σ2.
lll. A variância amostral calculada por \( \hat{ \sigma}^2 = { \large \sum_{i=1}^n (X_i - \bar{X}_n)^2 \over n} \) é um estimador consistente, porém apresenta um pequeno viés na estimação de σ2.
lV. Pode-se afirmar que \( var [ \bar{X}_n] = { \large \sigma \over \sqrt{n}} \).
Tendo como base estas afirmações, pode-se concluir que o número de afirmativas verdadeiras é
Provas
Um pesquisador, visando realizar uma estimação por Intervalo de Confiança para a média de uma população supostamente normal, ao nível de confiança de 95%, coletou uma amostra obtendo os seguintes valores para algumas estatísticas descritivas:
|
tamanho da amostra |
média amostral | desvio padrão amostral |
| 16 | 10 | 2 |
No programa estatístico R, a função qt(p=α, df=k) fornece o quantil a a% numa distribuição t-Student com k graus de liberdade. Assim por exemplo, qt(p=0.05, df=10) fornece o quantil a 5% numa distribuição t-Student com 10 graus de liberdade. O quadro abaixo apresenta alguns valores para esta função:
|
qt(p=0.025, df=15) = -2,13 |
Com base nesta situação, o valor mais próximo para a margem de erro a ser utilizada pelo pesquisador a partir das informações coletadas é
Provas
O gráfico a seguir destaca numa distribuição normal padrão a probabilidade de se obter um valor igual ou inferior ao número 1.
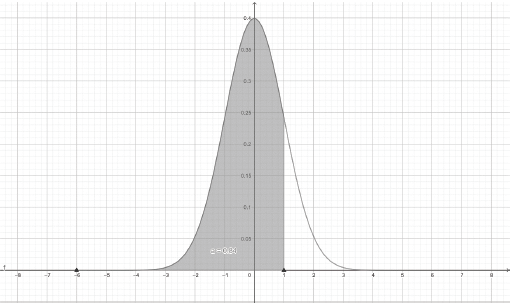
Para se obter o valor desta área do ponto de vista do cálculo diferencial deve-se calcular o valor de uma certa integral. Desta forma, a respectiva integral é descrita por
Provas
Um partido político, com intensão de estimar a proporção de eleitores que teriam preferência pelo seu candidato, numa pesquisa eleitoral para a prefeitura de uma determinada cidade, resolveu contratar um instituto de pesquisa para realizar tal ação. Este, elaborou com todas as metodologias estatísticas recomendadas, um plano amostral e indicou para o partido os custos na realização desta pesquisa. Neste plano, o instituto planejou a pesquisa para que a margem de erro na estimação da proporção fosse de apenas 2% e o nível de confiança de 95%. Isso implicou numa amostra de 2.300 eleitores. Porém, o partido político achou os gastos com a pesquisa muito altos e solicitou ao instituto responsável que apresentasse possibilidades de diminuir os custos, mas mantendo um padrão científico da pesquisa. Sendo assim, uma possibilidade verdadeiramente viável para diminuir o tamanho da amostra seria
Provas
Suponha que a altura das mulheres brasileiras na fase adulta de sua vida pode ser modelada por uma distribuição normal com média igual a 1,60m e desvio padrão igual a 20cm. Sendo Φ(x) a função de distribuição acumulada da normal padrão no ponto x. Se necessário utilize os valores aproximados de Φ(x) para alguns pontos. Sendo assim, o valor mais próximo para a probabilidade de que uma mulher brasileira selecionada aleatoriamente tenha uma altura superior a 1,80m é
| x |
Φ(x) |
| 0,20 |
0,58 |
| 1,00 | 0,84 |
| 1,60 | 0,95 |
| 1,80 | 0,96 |
| 2,00 | 0,98 |
Provas
Considere que a variável aleatória X tem distribuição binomial com parâmetros n = 100 e p = 0,5. Sendo assim, o valor do desvio padrão da variável X é
Provas
Caderno Container