Foram encontradas 70 questões.
É preciso estar atento e forte.
Sobre a estrutura sintática da frase em destaque, assinale a opção incorreta.
Provas
Considere a transformação linear T: \(\mathbb{R}^3 \rightarrow \mathbb{R}^2\) tal que T (−1,0,0)= (2,0), \( T \)(0,2,0) = (2,1) e \( T \)(0,0, −1) = (0, −1). Sendo \( T \)(\( x \), \( y \), \( z \)) = (\( a \)\( x \) + \( b \)\( y \) + \( c \)\( z \) , \( d \)\( x \) + \( e \)\( y \) + \( f \)\( z \)) a expressão dessa transformação linear, o valor de \( a \) + \( b \) + \( c \) + \( d \) + \( e \) + \( f \) é
Provas
Em um sistema de banco de dados relacional, o script de comandos SQL a seguir especificado foi submetido à execução:

A análise do script permite-nos afirmar que a sua execução produzirá um resultado.
Assinale a opção que indica esse resultado.
Provas
- Banco de Dados RelacionalDependência Funcional
- Banco de Dados RelacionalNormalização5FN: Quinta Forma Normal
No âmbito de normalização de bancos de dados relacionais, há o conceito de dependência com a seguinte especificação: “para o esquema de uma relação R, uma restrição que demanda que cada estado r de R apresente uma decomposição de junção não aditiva e não trivial para cada decomposição Ri de R, em que o valor de i varie entre 1 e n, sendo n o número de decomposições de R”.
Esse conceito de dependência, considerando um valor de n maior que dois (n>2), integra a definição da
Provas
Um dos conceitos associados a coleções de objetos de dados e/ou arquivos de sistemas de bancos de dados NoSQL é o de sharding. Nesse contexto, uma das características de sharding refere-se
Provas
O Apache Spark é uma ferramenta amplamente utilizada para processamento de grandes volumes de dados.
Assinale a opção que o descreve corretamente, assim como suas capacidades e suas funcionalidades.
Provas
O Apache Hadoop é uma plataforma amplamente utilizada no processamento de grandes volumes de dados. Ele se destaca por sua arquitetura distribuída e capacidade de lidar com grandes conjuntos de dados de forma eficiente.
Com base nas capacidades e funcionalidades do Hadoop, assinale a opção que = descreve corretamente seu funcionamento e aplicação prática.
Provas
Considere o seguinte código em R:

É correto afirmar que
Provas
Seja o conjunto de dados X apresentado a seguir, em que os atributos “P” e “Q” são preditores, e o atributo “Classe” é o atributo-alvo:
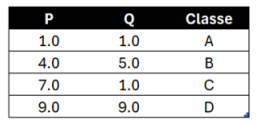
Queremos classificar uma nova amostra x=(5.0, 5.0) utilizando o algoritmo clássico dos k vizinhos mais próximos (k-NN), utilizando a distância euclidiana para a determinação de vizinhanças. Com base nesse algoritmo, e considerando os valores aproximados de √2 ≈ 1,414 e √3 ≈ 2,236, o k-NN retorna como categoria de x
Provas
Os modelos de dados desempenham um papel fundamental no processo de ETL (Extração, Transformação e Carga), pois são responsáveis por estruturar e organizar as informações de maneira eficiente e consistente. Eles garantem que os dados extraídos de diferentes fontes sejam integrados corretamente, facilitando a transformação e preparação para a análise posterior.
No contexto de modelos de dados em ETL, existe o conceito de tabela de fatos sem fato (factless fact), que se caracteriza por
Provas
Caderno Container