Foram encontradas 5.143 questões.
Acerca de governança de dados, julgue os itens que se seguem.
Se, nos dados de criação de suínos, um suíno foi registrado com 100 kg de peso e 2 meses de idade, então, como os valores registrados são incomuns para a espécie, tem-se, nesse caso, um exemplo de valores inconsistentes; essa discrepância pode indicar erro de preenchimento, como entrada incorreta de dados, ou a manipulação intencional para alterar informações e deve ser corrigida com técnicas como a remoção do registro inconsistente ou a substituição do peso por uma média calculada a partir de outros suínos da mesma idade.
Provas
Julgue os próximos itens, relativos a aprendizado de máquina.
Considere que, em um modelo de regressão linear ajustado para prever a produção de soja (Y, em sacas por hectare) com base na quantidade de fertilizante aplicado (X, em kg/ha), a equação estimada foi Y = 30 + 0,8X. Nesse caso, o coeficiente angular dessa equação indica que, ao aplicar 10 kg/ha a mais de fertilizante, espera-se um aumento de 8 sacas por hectare na produção de soja, e, sem aplicação de fertilizante, a produção esperada de soja será de 30 sacas por hectare.
Provas
Julgue os próximos itens, relativos a aprendizado de máquina.
O algoritmo de backpropagation, utilizado para treinar redes neurais, calcula o erro na saída da rede e ajusta os pesos da rede aleatoriamente, para minimizar o erro na próxima iteração.
Provas
Julgue os próximos itens, relativos a aprendizado de máquina.
O algoritmo k-NN é um método de aprendizado baseado em instâncias que classifica novos exemplares por meio de um modelo previamente treinado, o que dispensa a necessidade de armazenar os dados de treinamento para futuras comparações.
Provas
Julgue os próximos itens, relativos a matemática computacional e ciência da computação aplicada.
Ao se comparar os algoritmos de busca linear e de busca binária em um array ordenado com \( n \) elementos, verifica-se que a busca binária tem complexidade temporal O(log \( n \) ), enquanto a busca linear tem complexidade temporal O(\( n \)).
Provas
Julgue os próximos itens, relativos a matemática computacional e ciência da computação aplicada.
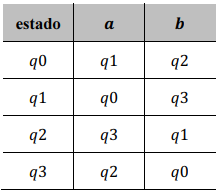
Para o autômato finito determinístico identificado por = ({\( a,b \) }, {\( q0, q1, q2, q3 \)}, \( \delta1 \), \( q0, \) {\( q3 \)}), em que \( \delta1 \) é dada pela tabela seguinte, é correta a afirmação: o autômato aceita a cadeia '\( abba \) '.
Provas
A respeito de visão computacional com redes neurais convolucionais (CNN), de classificação de imagens e de processamento de linguagem natural (PLN), julgue os itens seguintes.
Na classificação de imagens, o objetivo principal é atribuir um rótulo (classe) a cada pixel da imagem, delimitando e identificando diferentes objetos ou regiões, ao passo que, na segmentação de imagens, o objetivo é atribuir um único rótulo à imagem como um todo, indicando seu conteúdo principal.
Provas
A respeito de visão computacional com redes neurais convolucionais (CNN), de classificação de imagens e de processamento de linguagem natural (PLN), julgue os itens seguintes.
PLN é um campo da inteligência artificial voltado a capacitar máquinas na compreensão, interpretação e geração da linguagem humana. Aplicações como chatbots, tradutores automáticos e análise de sentimentos são exemplos de aplicações dessa tecnologia. Contudo, modelos recentes, como o Gemini e o GPT, embora compartilhem algumas similaridades com o PLN, têm sua base fundamental na aplicação de aprendizado profundo, uma abordagem que dispensa a necessidade de regras linguísticas explícitas e se concentra na identificação de padrões complexos em grandes conjuntos de dados.
Provas
Julgue os próximos itens, relativos a aprendizado de máquina e BI (Business Intelligence).
O algoritmo de agrupamento K-means — baseado em centroides, que divide um conjunto de dados em grupos semelhantes com base na distância entre seus centroides — pode ser utilizado para, a partir de uma base de dados de uma rede social, identificar comunidades de usuários com interesses comuns em determinados assuntos.
Provas
Julgue os próximos itens, relativos a aprendizado de máquina e BI (Business Intelligence).
Random forest é um método de aprendizado de conjunto que combina várias árvores de decisão para formar um modelo mais robusto e preciso. Tal método pode ser usado tanto para resolver problemas de regressão (por exemplo, prever o valor de uma ação) quanto para realizar classificação (por exemplo, compra válida, fraude).
Provas
Caderno Container