Foram encontradas 5.143 questões.
Disciplina: TI - Ciência de Dados e BI
Banca: OBJETIVA
Orgão: Pref. Nova Roma Sul-RS
Provas
No que se refere a modelagem dimensional, mineração de dados e big data, julgue os itens subsequentes.
No modelo CRISP-DM, a fase de preparação dos dados é caracterizada por atividades como análise da qualidade dos dados, exploração dos dados, geração dos primeiros insights e formulação de hipóteses.
Provas
No que se refere a modelagem dimensional, mineração de dados e big data, julgue os itens subsequentes.
Na modelagem dimensional, a chave da tabela de fatos corresponde à associação das chaves primárias das tabelas de dimensões.
Provas
No que se refere a modelagem dimensional, mineração de dados e big data, julgue os itens subsequentes.
Na mineração de dados, a tarefa de classificação consiste em descobrir uma função que mapeie um conjunto de registros de dados em um conjunto de variáveis predefinidas, e as redes neurais e back-propagation são tipos de algoritmos que se aplicam a essa tarefa.
Provas
A respeito de dado, informação, conhecimento e inteligência, julgue os itens a seguir.
Na fase de armazenamento do ciclo de vida dos dados, o foco principal é prover meios que ampliem os níveis de utilização desses dados, seja por ampliação das possibilidades de acesso via cópia, por obtenção de conjuntos para análise, ou por meio da disponibilização de recursos de visualização desses dados.
Provas
A respeito de dado, informação, conhecimento e inteligência, julgue os itens a seguir.
Na fase de armazenamento do ciclo de vida dos dados, o foco principal é prover meios que ampliem os níveis de utilização desses dados, seja por ampliação das possibilidades de acesso via cópia, por obtenção de conjuntos para análise, ou por meio da disponibilização de recursos de visualização desses dados.
Provas
No que se refere a modelagem dimensional, mineração de dados e big data, julgue o item subsequente.
Em big data, a premissa variedade refere-se ao acréscimo dos volumosos tipos de dados semiestruturados e não estruturados aos tradicionais conjuntos de dados estruturados das organizações, responsável por impor desafios contextuais adicionais para o armazenamento, o tratamento e a análise dos dados dessas organizações.
Provas
Os processos de coleta e organização de dados devem observar, com cuidado, um aspecto preconizado na Governança de Dados especialmente útil na elucidação de erros, mudanças nos processos e migrações de sistemas.
Esse aspecto, numa estrutura de governança, é conhecido como:
Provas
Maria está implementando o Audit-DataMart para apoiar análises sobre a quantidade de auditorias realizadas por cidade e por período. Para isso, Maria elaborou o modelo multidimensional de dados no qual a dimensão tempo se relaciona com a tabela fato duas vezes, uma representando a data de início da auditoria e a outra representando a data do fim da auditoria, conforme ilustrado a seguir.
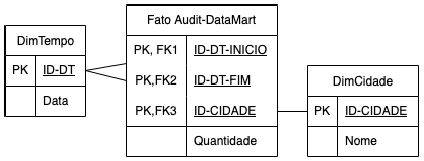
A técnica de modelagem multidimensional de dados utilizada por Maria para referenciar múltiplas vezes uma única dimensão física na tabela fato é:
Provas
No contexto de pré-processamento de dados, o auditor de contas públicas João está trabalhando em um projeto de análise de dados e percebe que as variáveis numéricas no conjunto de dados têm escalas muito diferentes, como a escala dos preços sendo maior do que a escala dos pesos, como demonstrado nos produtos A e B:
!$ \bullet !$ Produto A (Preço: R$ 50 e Peso: 300g)
!$ \bullet !$ Produto B (Preço: R$ 500 e Peso: 1000g)
Além disso, ele observa a presença de outliers nos dados. Nesse sentido, João deverá tratar os dados para garantir que as variáveis tenham uma distribuição normal, isto é, com média igual a zero e desvio padrão igual a um.
Para isso, a técnica de tratamento de dados que João deverá utilizar, levando em consideração a presença de outliers, é:
Provas
Caderno Container