Foram encontradas 40 questões.
As Redes Neurais Recorrentes (RNNs) são projetadas
para processar dados sequenciais ou temporais, destacando-se pela sua capacidade de reter memória de entradas
anteriores através de loops internos na sua arquitetura.
Entre os algoritmos mais utilizados, destacam-se o Long
Short-Term Memory (LSTM) e o Gated Recurrent Unit
(GRU), ambos projetados para preservar informações ao
longo do tempo e superar o desafio do desaparecimento
do gradiente. Além disso, técnicas fundamentais como
softmax, backpropagation e o processo feedforward são
fundamentais para o treinamento e a eficácia das RNNs.
Acerca dessas técnicas, a opção que apresenta uma observação INCORRETA é:
Provas
Questão presente nas seguintes provas
Considere a seguinte implementação de um modelo de
regressão linear múltipla utilizando NumPy e scikit-learn,
usado para prever o financiamento de projetos com base
em características de projetos e pesquisadores. O código
abaixo foi executado e algumas métricas de desempenho
foram obtidas.
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
Provas
Questão presente nas seguintes provas
O scikit-learn é uma biblioteca de aprendizado de máquina para Python que fornece uma ampla variedade de
classes e funções para análise de dados e modelagem de
Machine Learning. Ele inclui algoritmos para classificação,
regressão, clusterização, redução de dimensionalidade,
seleção de modelos, pré-processamento de dados, entre
outros.
Entre as opções abaixo, a que apresenta corretamente a combinação de classes e funções do scikit-learn usadas para implementar regressão do tipo polinomial e classificação com árvores de decisão é:
Entre as opções abaixo, a que apresenta corretamente a combinação de classes e funções do scikit-learn usadas para implementar regressão do tipo polinomial e classificação com árvores de decisão é:
Provas
Questão presente nas seguintes provas
Modelos de Machine Learning (ML) são parte fundamental do conhecimento no campo de um cientista de
dados, objetivando a compreensão de padrões complexos
e a tomada de decisão baseada em dados. Esses modelos
permitem que cientistas de dados transformem grandes
volumes de dados brutos em insights acionáveis, previsões
e recomendações com precisão que frequentemente supera
análises tradicionais.
Considerando a base de dados contendo projetos, pesquisadores, publicações e financiamentos, diversos modelos de aprendizado de máquina podem ser criados. Entre as opções abaixo, a que apresenta uma relação INCORRETA entre objetivo, tipo de aprendizado e tipo de algoritmo de aprendizado de máquina é:
Considerando a base de dados contendo projetos, pesquisadores, publicações e financiamentos, diversos modelos de aprendizado de máquina podem ser criados. Entre as opções abaixo, a que apresenta uma relação INCORRETA entre objetivo, tipo de aprendizado e tipo de algoritmo de aprendizado de máquina é:
Provas
Questão presente nas seguintes provas
Além da linguagem Python, a linguagem R é uma
poderosa ferramenta estatística e gráfica utilizada por cientistas de dados em todo o mundo. Originária do ambiente
acadêmico e com forte apoio da comunidade de estatística,
R rapidamente se consolidou como uma das linguagens de
programação de escolha para análise de dados, pesquisa
científica, e qualquer aplicação que exija manipulação intensiva de dados, análise estatística ou visualização gráfica.
Considere o sumário exibido abaixo, saída do comando summary(df) da linguagem R:
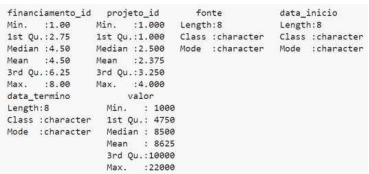
Com base nesta informação, a opção que contém uma observação INCORRETA é:
Considere o sumário exibido abaixo, saída do comando summary(df) da linguagem R:
Com base nesta informação, a opção que contém uma observação INCORRETA é:
Provas
Questão presente nas seguintes provas
Além do Pandas, NumPy, que é um acrônimo para
Numerical Python, é outra biblioteca fundamental para a
computação em Python. Ela serve como um dos pilares
do ecossistema de ciência de dados e análise numérica,
oferecendo suporte para poderosas estruturas de dados de
arrays e matrizes multidimensionais.
Seja o dataframe Pandas df carregado da tabela Financiamento e um extrato de seus dados mostrado abaixo.

E seja o seguinte código NumPy, que transforma df em matriz e manipula suas linhas e colunas.
import numpy as np matriz = df.values subconjunto = matriz[matriz[:, 1] == 1, 4:6]
Das opções abaixo, a que apresenta corretamente o array extraído pela operação NumPy é:
Seja o dataframe Pandas df carregado da tabela Financiamento e um extrato de seus dados mostrado abaixo.
E seja o seguinte código NumPy, que transforma df em matriz e manipula suas linhas e colunas.
import numpy as np matriz = df.values subconjunto = matriz[matriz[:, 1] == 1, 4:6]
Das opções abaixo, a que apresenta corretamente o array extraído pela operação NumPy é:
Provas
Questão presente nas seguintes provas
Quando se trabalha com grandes conjuntos de dados
no Pandas, a eficiente alocação de memória torna-se crucial
para manter um bom desempenho e evitar o esgotamento
dos recursos do sistema. Dado este desafio, analise as
opções abaixo para otimizar o uso da memória ao manipular
grandes volumes de dados com Pandas.
I. Empregar categorias para dados textuais repetitivos ao invés de strings.
II. Segmentar os dados em chunks menores durante a leitura de arquivos grandes, utilizando o parâmetro chunksize no read_csv.
III. Fazer uso intensivo de operações inplace.
Sobre as afirmativas acima, pode-se dizer que:
I. Empregar categorias para dados textuais repetitivos ao invés de strings.
II. Segmentar os dados em chunks menores durante a leitura de arquivos grandes, utilizando o parâmetro chunksize no read_csv.
III. Fazer uso intensivo de operações inplace.
Sobre as afirmativas acima, pode-se dizer que:
Provas
Questão presente nas seguintes provas
O campo da Ciência de Dados é dinâmico e está em
constante evolução, com o desenvolvimento de tecnologias
e ferramentas que tornam a análise de dados mais eficiente
e acessível. Uma dessas ferramentas é a biblioteca Pandas
para a linguagem de programação Python. Por ser uma
biblioteca de análise de dados conhecida principalmente
por suas estruturas de dados poderosas que facilitam a
manipulação de dados, como dataframes, é amplamente
utilizada em processos de ETL (Extract, Transform and
Load) por engenheiros e cientistas de dados que necessitam pré-processar e transferir dados entre plataformas de
dados, como, por exemplo, bancos de dados relacionais e
Data Lakes.
Considere o seguinte código Python que implementa parte de um ETL sobre a tabela Financiamento.
import pandas as pd from sqlalchemy import create_engine from datetime import datetime
engine = create_engine(“postgresql:// postgres:postgres@localhost:5432/bd_pesquisa”) query = “SELECT * FROM Financiamento” df = pd.read_sql_query(con=engine.connect(), sql=sql_text(query)) df[‘data_inicio’] = pd.to_datetime(df[‘data_ inicio’]).dt.strftime(‘%d/%m/%Y’) df[‘data_fim’] = pd.to_datetime(df[‘data_ fim’]).dt.strftime(‘%d/%m/%Y’) df.to_csv(‘financiamentos_transformados.csv’, index=False)
Observe as afirmativas a seguir sobre a execução do código.
I. O código se conecta a um banco de dados PostgreSQL usando a biblioteca SQLAlchemy e extrai todos os dados da tabela Financiamento.
II. As colunas data_inicio e data_fim são transformadas para o formato DD/MM/AAAA, mas esses dados não são atualizados no banco de dados.
III. O dataframe resultante da transformação é salvo em um arquivo CSV chamado financiamentos_transformados.csv na máquina local, incluindo o índice do datadrame como uma coluna adicional.
Sobre as afirmativas acima, pode-se dizer que:
Considere o seguinte código Python que implementa parte de um ETL sobre a tabela Financiamento.
import pandas as pd from sqlalchemy import create_engine from datetime import datetime
engine = create_engine(“postgresql:// postgres:postgres@localhost:5432/bd_pesquisa”) query = “SELECT * FROM Financiamento” df = pd.read_sql_query(con=engine.connect(), sql=sql_text(query)) df[‘data_inicio’] = pd.to_datetime(df[‘data_ inicio’]).dt.strftime(‘%d/%m/%Y’) df[‘data_fim’] = pd.to_datetime(df[‘data_ fim’]).dt.strftime(‘%d/%m/%Y’) df.to_csv(‘financiamentos_transformados.csv’, index=False)
Observe as afirmativas a seguir sobre a execução do código.
I. O código se conecta a um banco de dados PostgreSQL usando a biblioteca SQLAlchemy e extrai todos os dados da tabela Financiamento.
II. As colunas data_inicio e data_fim são transformadas para o formato DD/MM/AAAA, mas esses dados não são atualizados no banco de dados.
III. O dataframe resultante da transformação é salvo em um arquivo CSV chamado financiamentos_transformados.csv na máquina local, incluindo o índice do datadrame como uma coluna adicional.
Sobre as afirmativas acima, pode-se dizer que:
Provas
Questão presente nas seguintes provas
Para a construção de um sistema de apoio à pesquisa
e desenvolvimento na área de saúde, um modelo ER associado deve abranger entidades essenciais que facilitam
a gestão de dados de pesquisa, desenvolvimento de estudos epidemiológicos e monitoramento de saúde pública.
Este sistema poderia auxiliar na análise de tendências,
na resposta a emergências de saúde pública e no desenvolvimento de políticas de saúde baseadas em evidências.
Seja o diagrama ER apresentado abaixo, desenhado na notação crow’s foot, para um sistema de gestão de pesquisa.
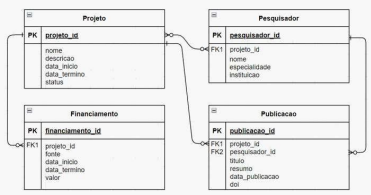
Entre as opções abaixo, a que apresenta corretamente uma consulta SQL para retornar o valor total de financiamento de um projeto chamado “Inovação em Saúde” é:
Seja o diagrama ER apresentado abaixo, desenhado na notação crow’s foot, para um sistema de gestão de pesquisa.
Entre as opções abaixo, a que apresenta corretamente uma consulta SQL para retornar o valor total de financiamento de um projeto chamado “Inovação em Saúde” é:
Provas
Questão presente nas seguintes provas
Com base no diagrama ER apresentado na questão
anterior, a consulta SQL que lista os nomes de todos os
projetos que estão associados a menos de 4 pesquisadores
e que têm um financiamento total maior que 20.000,00 é:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container