Foram encontradas 5.143 questões.
A normalização de dados é uma tarefa comum antes da implementação de uma IA ou algoritmo de Machine
Learning. É por meio da normalização que se garante uma mesma escala entre os dados, comumente entre
0 e 1 ou –1 e 1.
Sendo X o vetor de dados originais, e X' o vetor de dados normalizados, assinale a alternativa que descreve corretamente uma normalização válida.
Sendo X o vetor de dados originais, e X' o vetor de dados normalizados, assinale a alternativa que descreve corretamente uma normalização válida.
Provas
Questão presente nas seguintes provas
A figura mostra uma arquitetura de Rede Neural ________________, em que U, W e V são ________________.
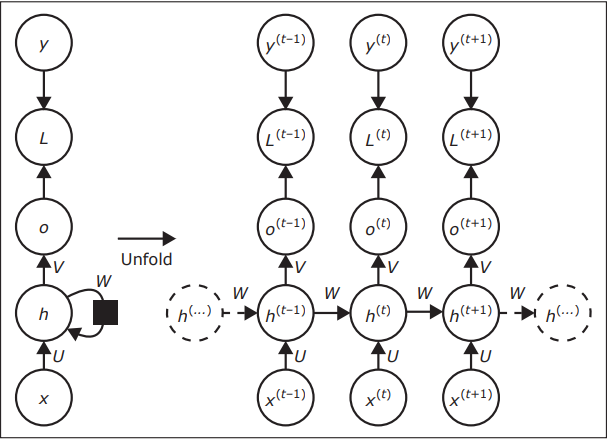
Fonte: GOODFELLOW et al. Deep Leaning. MIT press, 2016 (p. 378). (Adaptado)
Assinale a alternativa que completa corretamente as lacunas.
Provas
Questão presente nas seguintes provas
A Universidade X está integrando uma árvore de decisão, baseada em entropia, para prever a evasão dos
alunos. Em um cenário de testes, o número de reprovações se mostrou um atributo importante. Para tal,
criou-se a árvore, conforme a figura.
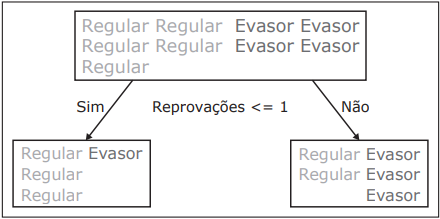
Considerando o nó inicial e seus filhos, assinale a alternativa correta quanto ao resultado que reflete a equação do ganho.
Considerando o nó inicial e seus filhos, assinale a alternativa correta quanto ao resultado que reflete a equação do ganho.
Provas
Questão presente nas seguintes provas
Modelos baseados em n-grams definem a probabilidade condicional de um n-th token, dados os n–1
tokens precedentes. Assinale a alternativa que indica
corretamente a técnica clássica à qual se refere a
frase dada.
Provas
Questão presente nas seguintes provas
Sobre o algoritmo Florestas Aleatórias (Random
Forests), considere as afirmativas a seguir.
I → Uma Floresta Aleatória é um método de conjunto projetado especificamente para a classificação com árvores de decisão.
II → Um exemplo de Floresta Aleatória é o algoritmo Ada Boost.
III → Bagging usando Árvores de Decisão é um caso especial de Florestas Aleatórias, em que a aleatoriedade é inserida no processo de construção do modelo, escolhendo aleatoriamente N exemplos, com substituição, a partir do conjunto de treinamento original.
Está(ão) correta(s)
I → Uma Floresta Aleatória é um método de conjunto projetado especificamente para a classificação com árvores de decisão.
II → Um exemplo de Floresta Aleatória é o algoritmo Ada Boost.
III → Bagging usando Árvores de Decisão é um caso especial de Florestas Aleatórias, em que a aleatoriedade é inserida no processo de construção do modelo, escolhendo aleatoriamente N exemplos, com substituição, a partir do conjunto de treinamento original.
Está(ão) correta(s)
Provas
Questão presente nas seguintes provas
Referente à arquitetura original do Transformer
(conforme o artigo “Attention is All You Need”, de
Vaswani et. al. 2017), qual é a principal vantagem
do uso do mecanismo Multi-Head Attention em
comparação com uma única camada de atenção na
arquitetura Transformer?
Provas
Questão presente nas seguintes provas
Observando-se uma típica Rede Neural feed-forward,
considere as afirmativas a seguir.
I → Número de camadas ocultas e taxa de aprendizagem são alguns dos parâmetros.
II → Neurônios, pesos, viés e função de ativação são partes de uma rede.
III → Número de camadas ocultas e números de neurônios para cada camada são alguns dos hiperparâmetros.
IV → O algoritmo de ajuste mais comum é chamado de Backpropagation.
Está(ão) correta(s)
I → Número de camadas ocultas e taxa de aprendizagem são alguns dos parâmetros.
II → Neurônios, pesos, viés e função de ativação são partes de uma rede.
III → Número de camadas ocultas e números de neurônios para cada camada são alguns dos hiperparâmetros.
IV → O algoritmo de ajuste mais comum é chamado de Backpropagation.
Está(ão) correta(s)
Provas
Questão presente nas seguintes provas
Redes Neurais Artificiais podem aproximar
qualquer função contínua com erro arbitrariamente
pequeno. São estruturas base para as diversas
aplicações em Inteligência Artificial, especialmente
em Deep Learning e mostram seu verdadeiro
potencial quando a quantidade de dados é
abundante. Porém, há problemas comuns a serem
observados ao treinar os modelos. Observe as
alternativas a seguir e marque a que corresponde
a um possível problema com redes neurais.
Provas
Questão presente nas seguintes provas
Em uma pesquisa sobre hábitos daqueles que passaram no concurso público X, gerou-se a seguinte
tabela como exemplo dos dados coletados.
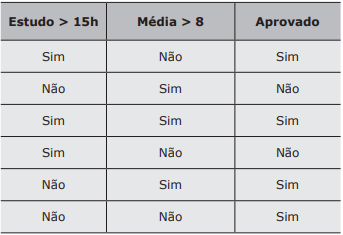
Hábitos vs Aprovação no Concurso X. A primeira coluna significa que o estudo semanal foi maior que 15h um mês antes do concurso. A segunda coluna refere-se à média final no curso superior. A coluna “Aprovado” refere-se a quem foi aprovado na primeira tentativa.
Para esta tabela, considerando a regra gerada pelo algoritmo Apriori, {Estudo>15h}→{Aprovado}, assinale a alternativa com a afirmação correta.
Hábitos vs Aprovação no Concurso X. A primeira coluna significa que o estudo semanal foi maior que 15h um mês antes do concurso. A segunda coluna refere-se à média final no curso superior. A coluna “Aprovado” refere-se a quem foi aprovado na primeira tentativa.
Para esta tabela, considerando a regra gerada pelo algoritmo Apriori, {Estudo>15h}→{Aprovado}, assinale a alternativa com a afirmação correta.
Provas
Questão presente nas seguintes provas
Há múltiplas maneiras de criar sistemas de recomendação. Uma das maneiras, baseada em mineração de dados, é identificar quais itens costumam
ocorrer em conjunto e posteriormente programá-las
no sistema. Tal problema é solucionado por algoritmos de associação que podem gerar regras ao estilo
setA→setB (leia-se, conjunto A implica conjunto B),
em que diversas métricas podem ser obtidas para
validar a força da regra.
Assinale a alternativa que, respectivamente, corresponde a um algoritmo de associação e a uma métrica usada para validar a regra.
Assinale a alternativa que, respectivamente, corresponde a um algoritmo de associação e a uma métrica usada para validar a regra.
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container