Foram encontradas 60 questões.
À medida que as organizações começaram a utilizar
múltiplos repositórios ou bancos de dados para armazenar
diferentes tipos de informações de negócios, a
necessidade de integrar os dados cresceu rapidamente e
ETL tornou-se o método padrão utilizado na construção de
Data Warehouse (DW). As ferramentas ETL em um Data
Warehouse (DW) possuem a função de:
Provas
Questão presente nas seguintes provas
Ao construir um classificador usando aprendizado de
máquina, um analista deve verificar o quão efetivo ele é
para a predição, ou seja, estimar sua precisão preditiva,
uma vez que o erro é inerente ao processo – deseja-se
aprender sobre uma população, mas se tem acesso a uma
amostra dela. No caso da classificação, o conjunto de
treinamento é utilizado para aprender e um conjunto de
testes é utilizado para estimar o erro. Para estimar a
precisão preditiva de um classificador a partir de uma
amostra de dados não utilizada anteriormente ou não
conhecida, podem ser empregadas as seguintes
estratégias:
Provas
Questão presente nas seguintes provas
Máquinas de vetores de suporte (do inglês, Support Vector
Machine - SVM) são algoritmos de aprendizado de
máquina que possibilitam a implementação de
classificadores. Os modelos implementados a partir desses
algoritmos utilizam funções kernel, conferindo como
vantagem:
Provas
Questão presente nas seguintes provas
Uma Rede Neural Convolucional (do inglês, Convolutional
Neural Network - CNN) é um algoritmo de aprendizado de
máquina profundo que pode, a partir dos dados de entrada,
atribuir importância (pesos e vieses que podem ser
aprendidos) a vários aspectos dos dados e, portanto, obter
maior diferenciação. São características da arquitetura das
redes neurais convolucionais:
Provas
Questão presente nas seguintes provas
O gráfico a seguir apresenta o comportamento de uma
rede neural artificial:
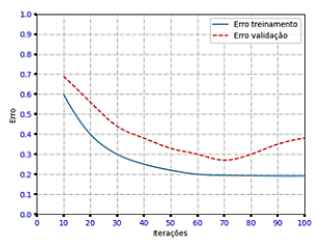
Considerando que o modelo foi validado como insatisfatório, as duas técnicas que podem contornar o problema apresentado são:
Considerando que o modelo foi validado como insatisfatório, as duas técnicas que podem contornar o problema apresentado são:
Provas
Questão presente nas seguintes provas
O LDA (do inglês, Latent Dirichlet Allocation) é um modelo
de aprendizado não supervisionado e estatístico utilizado
no Processamento de Linguagem Natural (PLN). No
processo de treinamento, o modelo LDA gera tópicos,
sendo que cada tópico incorpora uma quantidade de
palavras. Sob a mesma lógica, o resultado da aplicação do
LDA sobre um conjunto de documentos textuais pode ser
resumido como:
Provas
Questão presente nas seguintes provas
O Processamento de Linguagem Natural (PLN) é a área da
inteligência artificial que analisa, reconhece e/ou gera
textos em linguagens humanas (ou natural). Para
processar dados textuais, é necessário primeiramente
transformá-los em valores numéricos, sendo utilizados
algoritmos do tipo word embeddings, tais como glove, tf-idf,
word2vector e bag of words (BOW). São características do
algoritmo word2vector:
Provas
Questão presente nas seguintes provas
Os algoritmos de agrupamento buscam identificar padrões
existentes em conjuntos de dados, podendo ser do tipo
particionais, hierárquicos ou baseados na otimização da
função custo. É um exemplo de agrupamento hierárquico:
Provas
Questão presente nas seguintes provas
A multicolinearidade ocorre quando duas ou mais variáveis
independentes encontram-se altamente correlacionadas,
causando instabilidade na estimação dos parâmetros e
pode comprometer a interpretação dos modelos de
regressão. Uma técnica alternativa para lidar com a
multicolinearidade é a
Provas
Questão presente nas seguintes provas
Redes neurais recorrentes (RNNs) são modelos de
aprendizado profundo treinados para reconhecer padrões
em dados sequenciais (texto, imagens, genomas,
caligrafia, palavra falada ou dados de séries numéricas),
em que componentes se inter-relacionam com base em
regras complexas de semântica e sintaxe. São
características das redes neurais recorrentes:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container