Foram encontradas 110 questões.
Observe o Modelo de Entidades e Relacionamentos a seguir.
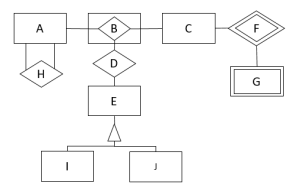
Com base nos relacionamentos apresentados, está explícito que:
Provas
Questão presente nas seguintes provas
Documentos do Jupyter Notebook são salvos com a extensão
.ipynb, mas internamente eles são documentos do tipo:
Provas
Questão presente nas seguintes provas
Igor, analista de dados da CVM, escreveu e rodou o código a
seguir.
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi:
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi:
Provas
Questão presente nas seguintes provas
Um cientista de dados utiliza a biblioteca scikit-learn para treinar
um estimador clf usando um conjunto de treinamento X1 e seu
respectivo conjunto de atributos-alvo y. Posteriormente, o
cientista estima os atributos-alvo do conjunto X2.
Para realizar o treinamento e a predição, o cientista de dados deve usar, respectivamente, os métodos:
Para realizar o treinamento e a predição, o cientista de dados deve usar, respectivamente, os métodos:
Provas
Questão presente nas seguintes provas
No método tensorflow.keras.layers.Dense(...), se nenhuma
função de ativação é especificada, é utilizada por padrão a
função:
Provas
Questão presente nas seguintes provas
- Compilação e Interpretação de CódigoAnálise Léxica
- Compilação e Interpretação de CódigoAnálise Sintática
- LinguagensPython
Considere o código python a seguir.
import spacy
nlp = spacy.load("pt_core_news_lg")
doc = nlp("O rato roeu a roupa do rei de Roma")
print(doc[2].pos_, doc[2].dep_)
Os valores exibidos pela última linha são:
Provas
Questão presente nas seguintes provas
- Conceitos BásicosTerminologiaRisco
- Proteção de DadosAnonimização e Pseudonimização
- Proteção de DadosProteção de Dados Pessoais
Uma certa organização gostaria de compartilhar dados com um
grupo de pesquisadores de uma universidade para a condução de
um estudo sobre problemas ergonômicos nos seus escritórios.
Entre os dados coletados, há informações sensíveis sobre seus
funcionários; portanto, o responsável pela coleta decidiu
anonimizar os dados. Isso foi feito removendo-se nomes e outros
campos identificadores e adicionando-se um número
identificador próprio a cada funcionário. Dessa forma, a
identidade dos funcionários seria preservada. Após a verificação
de uma amostra, o pesquisador responsável pelo estudo
recomendou medidas que deveriam ser aplicadas antes que os
dados pudessem ser aceitos para o estudo.
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
O problema que mais provavelmente motivou a recomendação do pesquisador e uma medida que pode mitigar esse problema são, respectivamente:
Provas
Questão presente nas seguintes provas
Considere o código python a seguir.
import torch
from torch import nn, Tensor
class CVMNet(nn.Module):
def __init__(self,
dim_in: int,
dim_hidden: int,
n_classes: int):
super().__init__()
self.i_layer = nn.Linear(dim_in, dim_hidden)
self.h_layer = nn.Sequential(
nn.Linear(dim_hidden, dim_hidden // 2),
nn.Tanh()
)
self.o_layer = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(dim_hidden // 2, n_classes),
nn.Softmax(dim=-1)
)
def forward(self, x: Tensor):
return self.o_layer(self.h_layer(self.i_layer(x)))
model = CVMNet(400, 100, 3)
pred = model(torch.eye(20).flatten()).detach()
Sobre a variável pred, é correto afirmar que:
Provas
Questão presente nas seguintes provas
Um dos principais fatores que tornam viável a aplicação de
modelos grandes de linguagem (LLMs) é o controle do espaço de
probabilidade de tokens através da redução de dimensionalidade
do vocabulário, sem perda da capacidade de reconstruir qualquer
token válido da linguagem sendo modelada.
Considerando esse objetivo, dois algoritmos que podem ser utilizados para esse fim são:
Considerando esse objetivo, dois algoritmos que podem ser utilizados para esse fim são:
Provas
Questão presente nas seguintes provas
Considere-se a aplicação de um modelo grande de linguagem
(LLM) com 3 bilhões de parâmetros, distribuído em formato não
quantizado, meia-precisão.
A quantidade mínima de memória necessária para carregar os pesos do modelo para inferência (sem gradientes), considerando apenas o espaço ocupado pelos pesos, é:
A quantidade mínima de memória necessária para carregar os pesos do modelo para inferência (sem gradientes), considerando apenas o espaço ocupado pelos pesos, é:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container