Foram encontradas 56.730 questões.
Sobre o padrão de projeto Iterator, onde, ao invés de percorrer uma estrutura com índices e ponteiros, há um objeto Iterator, com operações similares a begin, end, next. Suponha que várias estruturas de dados em uma biblioteca implementem Iterator.
Uma sintaxe comum para percorrer todos os itens de uma estrutura de dados E é:
tipo::iterator it;
for (it = E.begin(); it != E.end(); ++it) {
// algum código onde o valor de cada item é acessado com *it
}
onde 'tipo' é um tipo apropriado de estrutura de dados, por exemplo, std::vector<string>.
Marque a opção FALSA.
Provas
Para a questão, defina \( G_{n \times n} \) como um grafo não dirigido 2D grid com 4-vizinhança da seguinte forma:
(i,j) ↔ (i-1,j)
(i,j) ↔ (i+1,j)
(i,j) ↔ (i ,j-1)
(i,j) ↔ (i ,j+1)
onde as arestas não existem se alguma coordenada é < 1 ou > n. A Figura 1 (a seguir) mostra um exemplo para n = 5
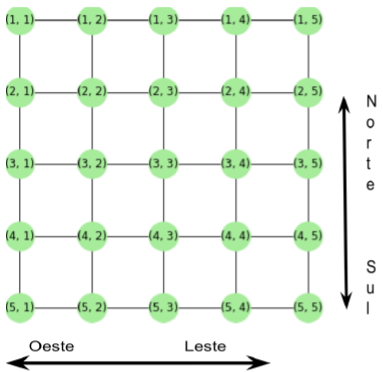
Suponha que os vizinhos de um vértice, durante a execução do DFS, são sempre listados na ordem Norte, Leste, Sul, Oeste, onde os pontos cardeais correspondem a uma realização do grafo sobre um sistema de coordenadas da forma trivial: o vértice (i,j) será colocado na coordenada (i,j), a primeira coordenada corresponde ao eixo Oeste (-) Leste (+), e a segunda ao eixo Sul (-) Norte (+), ainda correspondendo à figura anterior.
Suponha que o DFS inicia no vértice (1,1), e aplicamos a operação de contração sobre a árvore de busca DFS. Podemos afirmar:
Provas
Para a questão, defina \( G_{n \times n} \) como um grafo não dirigido 2D grid com 4-vizinhança da seguinte forma:
(i,j) ↔ (i-1,j)
(i,j) ↔ (i+1,j)
(i,j) ↔ (i ,j-1)
(i,j) ↔ (i ,j+1)
onde as arestas não existem se alguma coordenada é < 1 ou > n. A Figura 1 (a seguir) mostra um exemplo para n = 5
Ao aplicar o algoritmo DFS a \( G_{n \times n} \) para obter uma árvore de busca, contendo apenas as arestas entre sucessor e antecessor na busca DFS, podemos afirmar sobre esta árvore:
Provas
Para a questão, defina \( G_{n \times n} \) como um grafo não dirigido 2D grid com 4-vizinhança da seguinte forma:
(i,j) ↔ (i-1,j)
(i,j) ↔ (i+1,j)
(i,j) ↔ (i ,j-1)
(i,j) ↔ (i ,j+1)
onde as arestas não existem se alguma coordenada é < 1 ou > n. A Figura 1 (a seguir) mostra um exemplo para n = 5
Defina uma operação de 'contração' da seguinte forma:
para cada vértice u de grau 2
se u foi deletado, ignore e continue o 'para'.
v1 e v2 são os 2 vizinhos de u
se não existe aresta (v1,v2)
adicione ao grafo uma aresta (v1,v2)
delete u, (u,v1), (u,v2)
Se aplicarmos a operação de contração a \( G_{nxn} \), gerando um grafo \( G'_{nxn} \), quantos vértices e arestas a menos terá \( G'_{nxn} \) em relação ao grafo original, supondo n maior que 10:
Provas
Para a questão, defina \( G_{n \times n} \) como um grafo não dirigido 2D grid com 4-vizinhança da seguinte forma:
(i,j) ↔ (i-1,j)
(i,j) ↔ (i+1,j)
(i,j) ↔ (i ,j-1)
(i,j) ↔ (i ,j+1)
onde as arestas não existem se alguma coordenada é < 1 ou > n. A Figura 1 (a seguir) mostra um exemplo para n = 5
Marque a resposta mais exata e precisa. O número de arestas em \( G_{n \times n} \) é:
Provas
Para a questão, considere as seguintes funções de hash em pseudo-código para gerar códigos de hash para strings.
int P( char *s, int tablesize) {
return s[0] % tablesize;
}
int S( char *s, int tablesize) {
int sum = 0;
for (char *p = s; *p; p++)
sum = (sum + *p) % tablesize;
return sum;
}
Esta questão se refere a serviços P ou S que permite que usuários enviem strings que são armazenadas em uma tabela hash utilizando, respectivamente, as funções de hash de mesmo nome. Um atacante deseja rapidamente forçar que o tempo de busca de tais strings se torne \( \Theta \) (n) ao invés de O(1), através do envio ao servidor de um conjunto apropriado de strings.
Marque a opção FALSA.
Provas
Para a questão, considere as seguintes funções de hash em pseudo-código para gerar códigos de hash para strings.
int P( char *s, int tablesize) {
return s[0] % tablesize;
}
int S( char *s, int tablesize) {
int sum = 0;
for (char *p = s; *p; p++)
sum = (sum + *p) % tablesize;
return sum;
}
As alternativas comparam as duas funções em relação à conveniência de serem usadas como função de hash, considerando o tempo de busca médio.
Marque a alternativa FALSA.
Provas
Suponha um grafo onde os vértices são cidades, as arestas estradas entre cidades, e o peso das arestas corresponde a distância entre pares de cidades.
É possível, portanto, se for fornecido um valor da velocidade do veículo, usar Dijkstra para encontrar o caminho mais rápido entre 2 cidades, e obter o tempo gasto nesse caminho mínimo. Para isto, basta modificar o custo das arestas para indicar o tempo = distância / velocidade e não a distância.
Qual das seguintes variações do problema exige, para ser resolvida, modificar o algoritmo Dijkstra original, não sendo possível utilizar o Dijstra inalterado, como caixa preta, e apenas modificar o grafo de entrada, inclusive a escolha dos vértices inicial e final?
Marque a alternativa CORRETA.
Provas
Sobre o algoritmo de Dijkstra para encontrar caminhos mínimos sobre um grafo \( G=(V,E) \) não-dirigido e com pesos nas arestas. Uma variação comum do algoritmo armazena em cada nó um ponteiro u.p para o seu antecessor no caminho mais curto da raiz até ele. Chame essa variação de DijkstraP.
Defina: o subgrafo S(G) = (V,E’) como um subgrafo de G, cujos vértices são os mesmos de G, mas E’ é um subconjunto de E. Uma aresta (u,v) de E pertence a E’ apenas se, depois de executado DijsktraP, v.p = u;
Marque a alternativa FALSA:
Provas
Na programação paralela com aceleradores, como em CUDA, é preciso considerar os espaços de endereçamento acessíveis pelo código executando em CPU e pelo código executado em GPU.
// código 1:
int N = 1<<20;
float *x, *y, *d_x, *d_y;
x = (float*)malloc(N*sizeof(float));
y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float));
cudaMalloc(&d_y, N*sizeof(float));
// inicia elementos dos vetores x e y
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
// invoca kernel para manipulação de x e y
kern <<< ..., ... >>> (N, d_x, d_y);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
// código 2:
int N = 1<<20;
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// inicia elementos dos vetores x e y
...
// invoca kernel para manipulação de x e y
kern <<< ..., ... >>> (N, x, y);
cudaDeviceSynchronize();
Observe os 2 trechos de código apresentados anteriormente e indique a alternativa INCORRETA (próxima página):
Provas
Caderno Container