Foram encontradas 24.804 questões.
Provas
Provas
Provas
Provas
No modelo Entidade-Relacionamento (ER), uma característica importante, que tipifica um relacionamento, é a quantidade de ocorrências de uma entidade que podem estar associadas a um determinado relacionamento.
Essa propriedade é chamada de
Provas
Provas
As afirmativas abaixo se referem ao banco de dados Postgresql.
I. A instalação padrão do Postgresql utiliza a porta 6543 do protocolo para receber conexões.
II. O programa usado comumente para carregar cópias de uma base de dados a partir de um arquivo de texto é o psql.
III. Para especificar que uma base de dados deve tentar ser recuperada em uma única transação, é possível passar o parâmetro “-1”.
IV. Ao recuperar uma base de dados, se for encontrado um erro de SQL, o comportamento padrão do utilitário psql é perguntar ao usuário o que ele deseja fazer.
Estão corretas apenas as afirmativas
Provas
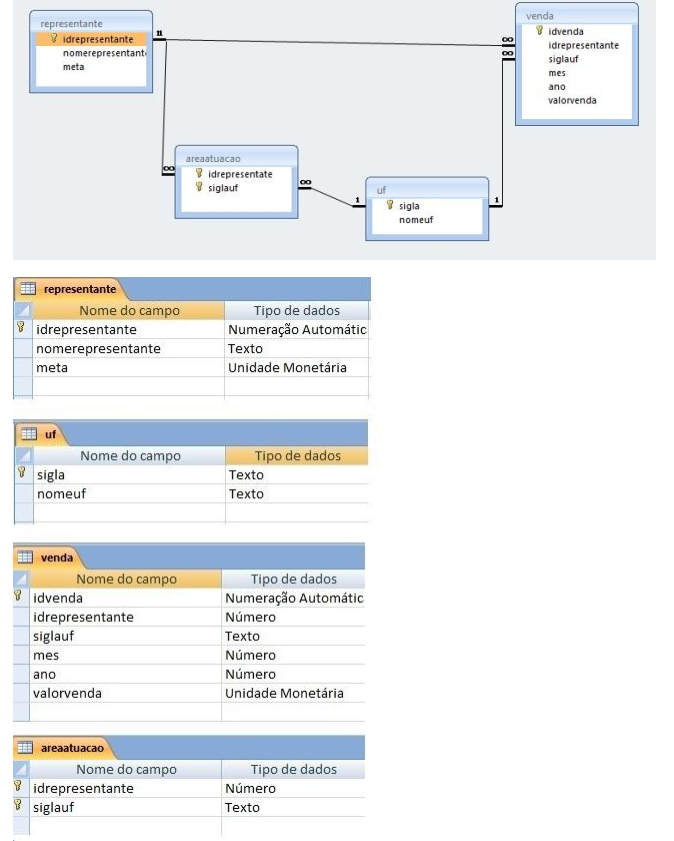
Provas
Provas
Provas
Caderno Container